Lancement de Ranystyle 0.0.999 (version de développement)

Table des matières
J’ai le plaisir de lancer la première version de développement de Ranystyle ! Ranystyle (prononcez “R-anystyle”) est conçu pour extraire, analyser et nettoyer les références bibliographiques à partir d’un éventail de sources, y compris les PDF, les documents .txt et les références stockées dans un objet R. A la base, Ranystyle exploite la puissance du Ruby Gem anystyle, en intégrant (et en étendant) ses capacités dans une interface R intuitive.
Installation initiale
Vous pouvez installer la version de développement de Ranystyle depuis GitHub avec :
# install.packages("devtools")
devtools::install_github("agoutsmedt/Ranystyle")
Avant de plonger dans les fonctionnalités de Ranystyle, assurez-vous que Ruby et RubyGems sont installés sur votre système. Si vous ne vous êtes pas encore aventuré dans le monde de Ruby, ne vous inquiétez pas ! L’installation est simple, et une fois installé, Ranystyle s’occupera du reste.
Pour installer automatiquement les gemmes Ruby anystyle et anystyle-cli, lancez simplement :
library(Ranystyle)
install_anystyle()
Utiliser Ranystyle dans votre workflow
Ranystyle peut être votre ressource de référence dans divers scénarios :
- Extraire des références de plusieurs PDF et les convertir au format
.bib. - Construire un tableau de données structuré à partir de références citées dans plusieurs PDF.
- Analyse d’un vecteur de références stocké dans un objet R pour en extraire des informations détaillées.
- Convertir la bibliographie d’un PDF d’un style de citation à un autre.
Création d’un fichier .bib à partir d’une collection de PDF
La fonction find_ref() exploite la puissance de la fonction find d'anystyle pour identifier les sections de référence et les notes de bas de page. Elle extrait les références citées dans un PDF. Imaginons que l’on dispose d’un ensemble de PDF et que l’on veuille en extraire les références (nous prenons ici les PDF stockés dans le paquet) :
library(Ranystyle)
# Locating the PDF documents bundled with the package
pdf_path <- system.file("extdata", package = "Ranystyle")
pdf_files <- list.files(pdf_path, pattern = "pdf$", full.names = TRUE)
pdf_files
## [1] "C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_1.pdf"
## [2] "C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_2.pdf"
## [3] "C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_3.pdf"
Visualisons la première page de références d’un de ces PDF :
# Leveraging pdftools to extract a page as an image
library(pdftools)
page_image <- pdftools::pdf_convert(pdf = pdf_files[1],
format = 'png',
pages = 22)
## Converting page 22 to example_doc_1_22.png... done!
knitr::include_graphics(page_image)

Ensuite, nous extrayons les références, en les sauvegardant dans le format [.bib] (https://fr.wikipedia.org/wiki/BibTeX).
find_ref(input = pdf_files[1],
path = getwd(),
output_format = "bib",
overwrite = TRUE)
## [1] "anystyle --overwrite -f bib find C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_1.pdf C:/Users/goutsmedt/Documents/MEGAsync/Research/R/projets/website/content/en/post/2024-01-09-release-ranystyle-development"
Pour illustrer l’efficacité de l’extraction, examinons les premières lignes du fichier .bib généré :
# Locating and reading the .bib file corresponding to the first PDF
bib_file <- sub("pdf$", "bib", basename(pdf_files[1]))
# Read the first 10 lines of the .bib file
bib_lines <- readLines(bib_file, n = 26)
# Print the lines
cat(bib_lines, sep = "\n")
## @article{arnold2023a,
## author = {Arnold, M.},
## date = {2023},
## title = {ECB must do more to tackle inflation “Monster”, says christine lagarde’},
## journal = {Financial Times}
## }
## @article{barro1983a,
## author = {Barro, R.J. and Gordon, D.B.},
## date = {1983},
## title = {Rules, discretion and reputation in a model of monetary policy’},
## volume = {12},
## pages = {101–121},
## url = {https://doi.org/10.1016/0304-3932(83)90051-X.},
## doi = {10.1016/0304-3932(83)90051-X.},
## journal = {Journal of Monetary Economics},
## number = {1}
## }
## @article{b2009a,
## author = {Béland, D.},
## date = {2009},
## title = {Ideas, institutions, and policy change’},
## volume = {16},
## pages = {701–718},
## journal = {Journal of European Public Policy},
## number = {5}
## }
Transformer des références PDF en un tableau de données
Ranystyle comble le fossé entre le contenu statique des PDF et l’analyse dynamique des données. En utilisant la fonction find_ref_to_df(), vous pouvez convertir les références des PDFS directement dans un tableau de données, plus précisément dans un tibble, pour une meilleure utilisation et manipulation dans l’écosystème tidyverse.
Voyons comment cela fonctionne :
# Extracting references from PDFs into a data frame
extracted_refs <- find_ref_to_df(input = pdf_files)
## [1] "anystyle -f json find C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_1.pdf "
## [1] "anystyle -f json find C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_2.pdf "
## [1] "anystyle -f json find C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_3.pdf "
## [1] "anystyle --overwrite -f ref find C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_1.pdf ./"
## [1] "anystyle --overwrite -f ref find C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_2.pdf ./"
## [1] "anystyle --overwrite -f ref find C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_3.pdf ./"
head(extracted_refs)
## # A tibble: 6 × 24
## id_doc doc id_ref author title year `container-title` volume pages
## <int> <chr> <chr> <list> <chr> <int> <chr> <chr> <chr>
## 1 1 example_doc… 1_1 <tibble> ECB … 2023 Financial Times <NA> <NA>
## 2 1 example_doc… 1_2 <tibble> Rule… 1983 Journal of Monet… 12 101–…
## 3 1 example_doc… 1_3 <tibble> Idea… 2009 Journal of Europ… 16 701–…
## 4 1 example_doc… 1_4 <tibble> A st… 1999 Scottish Journal… 46 17–39
## 5 1 example_doc… 1_5 <tibble> Tech… 2018 International Po… 12 328–…
## 6 1 example_doc… 1_6 <tibble> Late… 2003 Journal of Machi… 3 <NA>
## # ℹ 15 more variables: location <chr>, publisher <chr>, type <chr>, date <chr>,
## # other_date <chr>, other_title <chr>, url <chr>, issue <chr>, doi <chr>,
## # edition <chr>, genre <chr>, note <chr>, editor <chr>,
## # `collection-title` <chr>, full_ref <chr>
La fonction find_ref_to_df() ne se contente pas d’extraire les références, elle intègre également la possibilité d’un nettoyage supplémentaire via clean_ref(). Bien que le nettoyage automatisé soit disponible, le raffinement manuel est également une option. Cette double approche garantit la flexibilité et vous permet de garder le contrôle sur la qualité des données. Dans tous les cas, find_ref_to_df() crée un tableau de données contenant à la fois les informations extraites et les références complètes originales.
# Preview the original full references for manual inspection and cleaning
head(extracted_refs$full_ref)
## [1] "Arnold, M. (2023). ECB must do more to tackle inflation “Monster”, says christine lagarde’. Financial Times"
## [2] "Barro, R. J., & Gordon, D. B. (1983). Rules, discretion and reputation in a model of monetary policy’. Journal of Monetary Economics, 12(1), 101–121. https://doi.org/10.1016/0304-3932(83)90051-X"
## [3] "Béland, D. (2009). Ideas, institutions, and policy change’. Journal of European Public Policy, 16(5), 701–718"
## [4] "Berger, H., & Haan, J. (1999). A state within the state? An event study on the bundesbank (1948–1973)’. Scottish Journal of Political Economy, 46(1), 17–39"
## [5] "Best, J. (2018). Technocratic exceptionalism: Monetary policy and the fear of democracy’. International Political Sociology, 12(4), 328–345"
## [6] "Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent Dirichlet Allocation’. Journal of Machine Learning Research, 3"
Traitement des références basées sur des chaînes de caractères
Il peut arriver que des références soient déjà stockées sous forme de chaînes de caractères dans R, comme ceci :
# Sample references in string format
references <- c("Thiemann, Matthias, Carolina Raquel Melches, and Edin Ibrocevic. 2021. “Measuring and Mitigating Systemic Risks: How the Forging of New Alliances Between Central Bank and Academic Economists Legitimize the Transnational Macroprudential Agenda.\" Review of international political economy 28 (6): 1433-1458",
"Dietsch, Peter, François Claveau, and Clément Fontan. 2018. Do Central Banks Serve the People? New York: John Wiley & Sons",
"Singleton, John. 2010. Central Banking in the Twentieth Century. Cambridge: Cambridge University Press",
"Mudge, Stephanie L., and Antoine Vauchez. 2018. “Too Embedded to Fail.” Historical Social Research/Historische Sozialforschung 43(3): 248-273",
"Lucas, Robert E. 1972. “Expectations and the Neutrality of Money”. Journal of Economic Theory 4(2): 103-124")
references
## [1] "Thiemann, Matthias, Carolina Raquel Melches, and Edin Ibrocevic. 2021. “Measuring and Mitigating Systemic Risks: How the Forging of New Alliances Between Central Bank and Academic Economists Legitimize the Transnational Macroprudential Agenda.\" Review of international political economy 28 (6): 1433-1458"
## [2] "Dietsch, Peter, François Claveau, and Clément Fontan. 2018. Do Central Banks Serve the People? New York: John Wiley & Sons"
## [3] "Singleton, John. 2010. Central Banking in the Twentieth Century. Cambridge: Cambridge University Press"
## [4] "Mudge, Stephanie L., and Antoine Vauchez. 2018. “Too Embedded to Fail.” Historical Social Research/Historische Sozialforschung 43(3): 248-273"
## [5] "Lucas, Robert E. 1972. “Expectations and the Neutrality of Money”. Journal of Economic Theory 4(2): 103-124"
Dans ce cas, la fonction parse' d'anystyle, incorporée dans [Ranystyle](https://agoutsmedt.github.io/Ranystyle/index.html) [parse_ref()](https://agoutsmedt.github.io/Ranystyle/reference/parse_ref.html) et [parse_ref_to_df()](https://agoutsmedt.github.io/Ranystyle/reference/find_ref_to_df.html), devient votre solution de choix. Alors que [parse_ref()](https://agoutsmedt.github.io/Ranystyle/reference/parse_ref.html) vous permet de créer un fichier .bib(ou un autre format de fichier commejson`), parse_ref_to_df() transforme ces références en un cadre de données structuré :
# Parsing string references into a data frame
extracted_refs <- parse_ref_to_df(input = references)
## [1] "anystyle --no-overwrite -f json parse ref_to_parse.txt "
head(extracted_refs)
## # A tibble: 5 × 14
## id_doc doc id_ref author title year `container-title` volume pages
## <int> <chr> <chr> <list> <chr> <int> <chr> <chr> <chr>
## 1 1 ref_to_pars… 1_1 <tibble> Meas… 2021 Review of intern… 28 1433…
## 2 1 ref_to_pars… 1_2 <tibble> Do C… 2018 <NA> <NA> <NA>
## 3 1 ref_to_pars… 1_3 <tibble> Cent… 2010 <NA> <NA> <NA>
## 4 1 ref_to_pars… 1_4 <tibble> Too … 2018 Historical Socia… 43 248–…
## 5 1 ref_to_pars… 1_5 <tibble> Expe… 1972 Journal of Econo… 4 103–…
## # ℹ 5 more variables: location <chr>, publisher <chr>, type <chr>, date <chr>,
## # issue <chr>
Transformer sans effort les styles bibliographiques dans Word
La polyvalence de Ranystyle va au-delà de la manipulation de données et de la création de fichiers .bib. Supposons que vous ayez besoin de transférer directement des références dans un document Word, peut-être pour modifier le style de référencement. Dans ce cas, find_ref_to_word_bibliography vient à votre rescousse[^1]. Cette fonction est idéale pour modifier facilement le style bibliographique :
[^1] : Si vous souhaitez créer une bibliographie Word à partir de références stockées dans R, utilisez parse_ref_to_word_bibliography().
# Transforming PDF references into a Word document with a specific style
find_ref_to_word_bibliography(input = file.path(pdf_path, pdf_files[1]),
csl_path = "path/to/your_style.csl")
Voici un exemple de bibliographie générée :
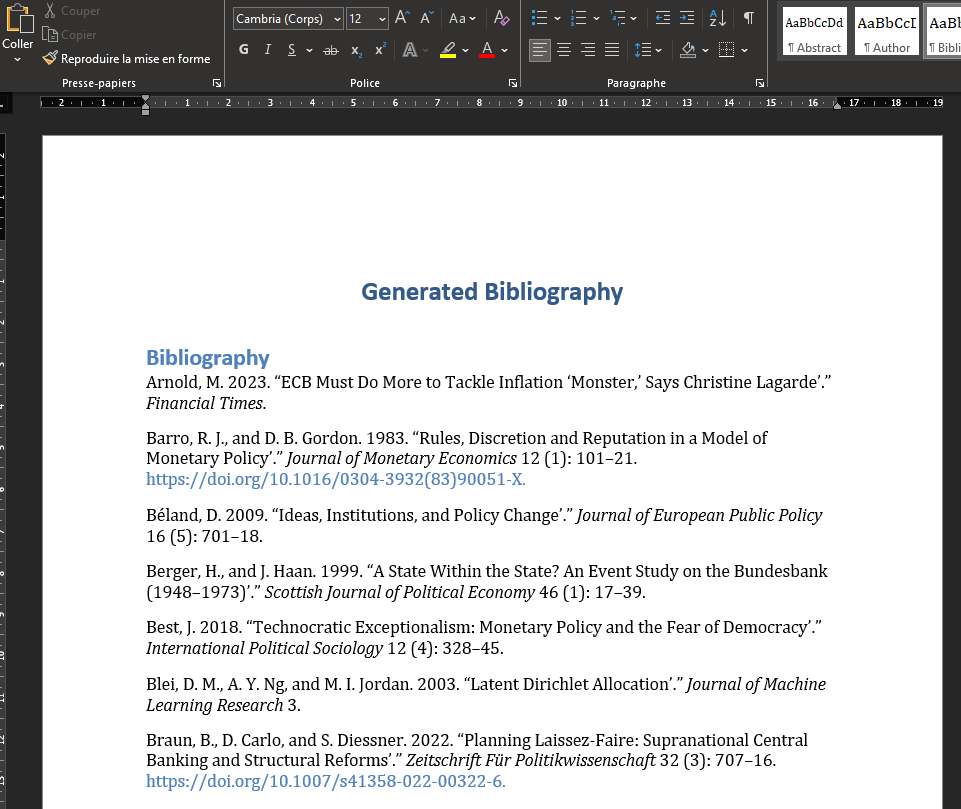
Explorer les possibilités avec Ranystyle
Les exemples ci-dessus ne sont qu’un aperçu du potentiel de Ranystyle. N’hésitez pas à approfondir chaque fonction et à explorer la vignette du package pour une compréhension complète de ce que Ranystyle peut faire.
Comme Ranystyle en est encore à ses débuts, votre retour est inestimable. Merci de partager vos expériences, signaler tout problème, suggérer des améliorations ou proposer de nouvelles fonctionnalités. Votre contribution sera déterminante pour affiner et améliorer les capacités de Ranystyle.
Crédits
anystyle, un composant central de Ranystyle, a été développé par une équipe talentueuse : Alex Fenton, Sylvester Keil, Johannes Krtek et Ilja Srna. anystyle est sous copyright : Copyright 2011-2018 Sylvester Keil. Tous droits réservés. Voir la Licence pour plus de détails.
Le logo Ranystyle a été créé à partir de DALL-E.
Aurélien Goutsmedt
Chercheur Postdoctoral et Chargé de Cours
Je travaille sur l’histoire de l’économie et l’expertise économique.