Moissonner les documents de travail de la Banque Centrale Européenne
Scraping Tutorials 2
Table des matières
Après un premier billet sur le scraping de la base de données des discours de la Banque des règlements internationaux, ce billet vous apprend à moissonner les documents du site de la Banque centrale européenne. Plus précisément, nous ne récupérerons pas les discours des membres du conseil d’administration de la BCE, car ils sont déjà disponibles au format .csv ici. Nous allons plutôt nous attaquer aux documents de recherche via les différentes séries de documents de travail publiés par la BCE.
Dans le billet précédent, nous avons appris la différence entre les pages web statiques et dynamiques. Les pages web dynamiques impliquent une interaction avec votre navigateur web : dans ce cas, vous avez besoin du pacquet RSelenium (Harrison 2022).1.
Là encore, nous serons confrontés à des pages web dynamiques. Cependant, ces pages web soulèvent de nouvelles questions. Avec la base de données de la BRI, le principal problème était de passer à la page suivante pour récupérer les métadonnées des discours suivants. Nous l’avons fait en trouvant comment le numéro de page était intégré dans l’URL. Avec le site de la BCE, le problème sera plus délicat pour deux raisons :
- Premièrement, tous les documents sont sur la même page mais comme la page peut être très longue (en fonction du type de documents), la page n’est pas entièrement chargée par votre navigateur. Vous devrez donc faire défiler la page vers le bas jusqu’à ce que tous les documents soient chargés.
- Deuxièmement, certaines informations (comme le résumé ou les codes JEL d’un document de travail) sont cachées, et vous devez cliquer sur un bouton pour les afficher.
Avant d’explorer cela en détail, chargeons les paquets nécessaires. Cette fois, nous utiliserons rvest (Wickham 2022) en complément de RSelenium et polite (Perepolkin 2023). A la fin de ce billet, nous testerons une seconde méthode avec rvest uniquement et non RSelenium pour récupérer des documents de travail.
# pacman is a useful package to install missing packages and load them
if(! "pacman" %in% installed.packages()){
install.packages("pacman", dependencies = TRUE)
}
pacman::p_load(tidyverse,
RSelenium,
rvest,
polite,
glue)
Un coup d’œil sur le site de la BCE
Supposons que nous voulions extraire les métadonnées des “occasional papers” de la BCE à l’adresse “https://www.ecb.europa.eu/pub/research/occasional-papers/html/index.en.html”.
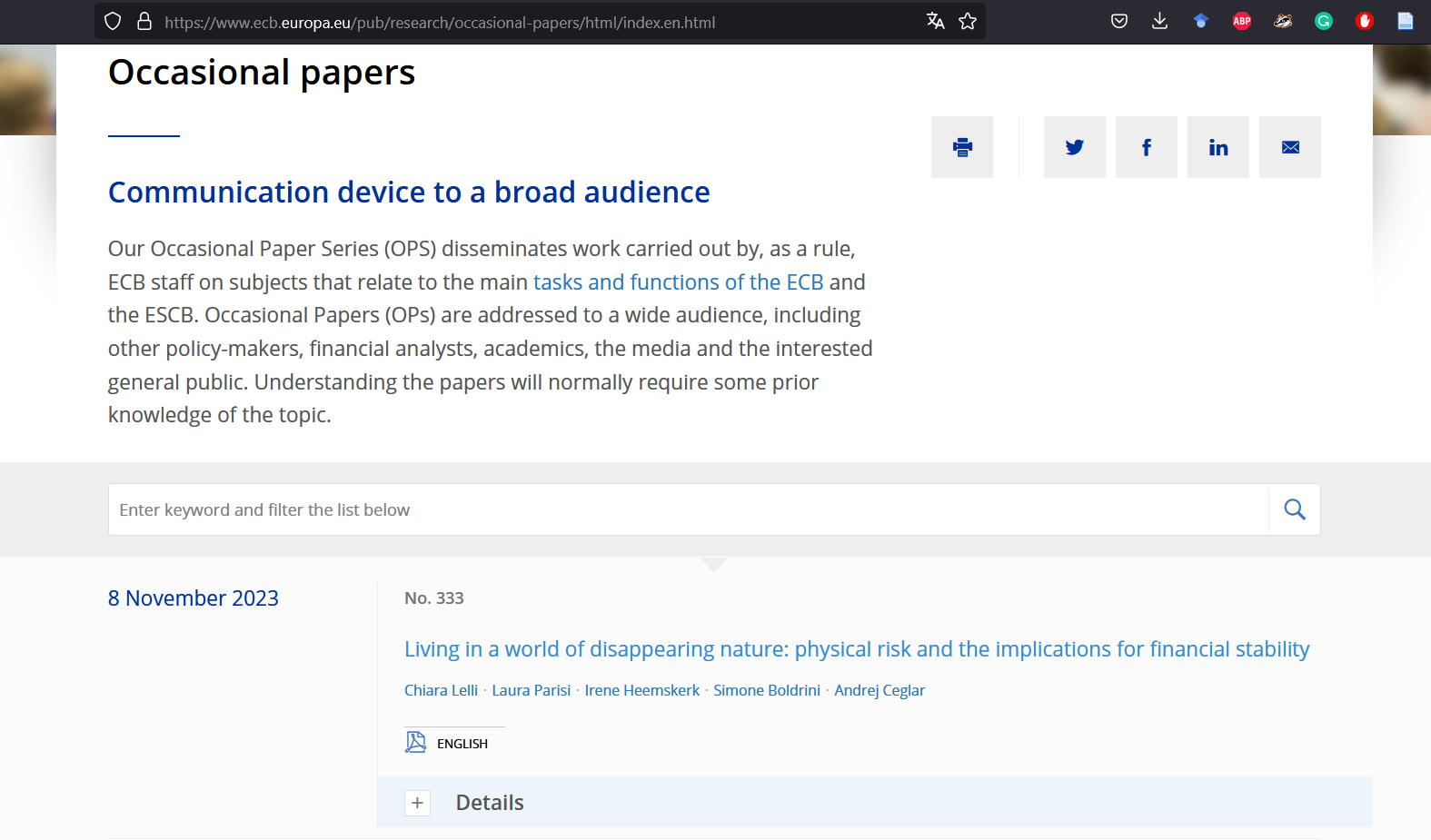
Figure 1: Les ‘occasional papers’ de la BCE
Nous pouvons voir qu’il y a 333 occasional papers sur le site de la BCE. Essayons de les scraper. Tout d’abord, nous utilisons polite pour nous “incliner” devant le site de la BCE. Nous spécifions qui nous sommes dans le paramètre user_agent, afin que le webmaster puisse nous contacter en cas de problème. En effet, nous essayons ici de suivre certaines règles éthiques en matière de scraping (voir quelques précisions sur cette question ici). La fonction bow() nous permet de vérifier les permissions pour le scraping.
ecb_op_path <- "https://www.ecb.europa.eu/pub/research/occasional-papers/html/index.en.html"
session <- bow(ecb_op_path,
user_agent = "polite R package - used for https://github.com/agoutsmedt/central_bank_database (aurelien.goutsmedt[at]uclouvain.be)")
session
## <polite session> https://www.ecb.europa.eu/pub/research/occasional-papers/html/index.en.html
## User-agent: polite R package - used for https://github.com/agoutsmedt/central_bank_database (aurelien.goutsmedt[at]uclouvain.be)
## robots.txt: 32 rules are defined for 1 bots
## Crawl delay: 5 sec
## The path is scrapable for this user-agent
En examinant le fichier robots.txt, nous pouvons voir plus en détail quels chemins du site web sont moissonnables ou non. Rien sur le chemin relatifs aux publications de recherche ici, la voie est libre !
cat(session$robotstxt$text)
## User-agent: *
## Sitemap: https://www.ecb.europa.eu/sitemap.xml
## Disallow: /*_content.bg.html$
## Disallow: /*_content.cs.html$
## Disallow: /*_content.da.html$
## Disallow: /*_content.de.html$
## Disallow: /*_content.el.html$
## Disallow: /*_content.en.html$
## Disallow: /*_content.es.html$
## Disallow: /*_content.et.html$
## Disallow: /*_content.fi.html$
## Disallow: /*_content.fr.html$
## Disallow: /*_content.ga.html$
## Disallow: /*_content.hr.html$
## Disallow: /*_content.hu.html$
## Disallow: /*_content.it.html$
## Disallow: /*_content.lt.html$
## Disallow: /*_content.lv.html$
## Disallow: /*_content.mt.html$
## Disallow: /*_content.nl.html$
## Disallow: /*_content.pl.html$
## Disallow: /*_content.pt.html$
## Disallow: /*_content.ro.html$
## Disallow: /*_content.sk.html$
## Disallow: /*_content.sl.html$
## Disallow: /*_content.sv.html$
## Disallow: /ecb/10ann/shared/movies/
## Disallow: /ecb/educational/pricestab/shared/movie/
## Disallow: /ecb/educational/shared/movies/
## Disallow: /paym/coll/assets/html/dla/EA/
## Disallow: /press/tvservices/webcast/shared/video/
## Disallow: /paym/coll/assets/html/dla/EA/
## Disallow: /events/conferences/shared/movie/
## Disallow: /euro/changeover/shared/data/
## Crawl-delay: 5
Nous pouvons lancer le robot :
remDr <- rsDriver(browser = "firefox",
port = 4444L,
chromever = NULL)
browser <- remDr[["client"]]
browser$navigate(ecb_op_path)
Sys.time(session$delay) # letting the page load
browser$findElement("css", "a.cross.linkButton.linkButtonLarge.floatRight.highlight-extra-light")$clickElement() # Refusing cookies
Défilement vers le bas et ouverture de menus supplémentaires
Nous pouvons essayer quelque chose rapidement : nous extrayons la liste des numéros des occasional papers (l’information “No. XXX” juste au-dessus du titre).
categories <- browser$findElements("css selector", ".category") %>%
map_chr(., ~.$getElementText()[[1]])
tail(categories)
## [1] "No. 315" "No. 314" "No. 313" "No. 312" "No. 311" "No. 310"
Nous avons quelque chose qui cloche ici. Le dernier article de la liste est No. 310. Mais si nous faisons défiler la page jusqu’en bas, nous pouvons voir que le dernier document devrait être “No. 1”.
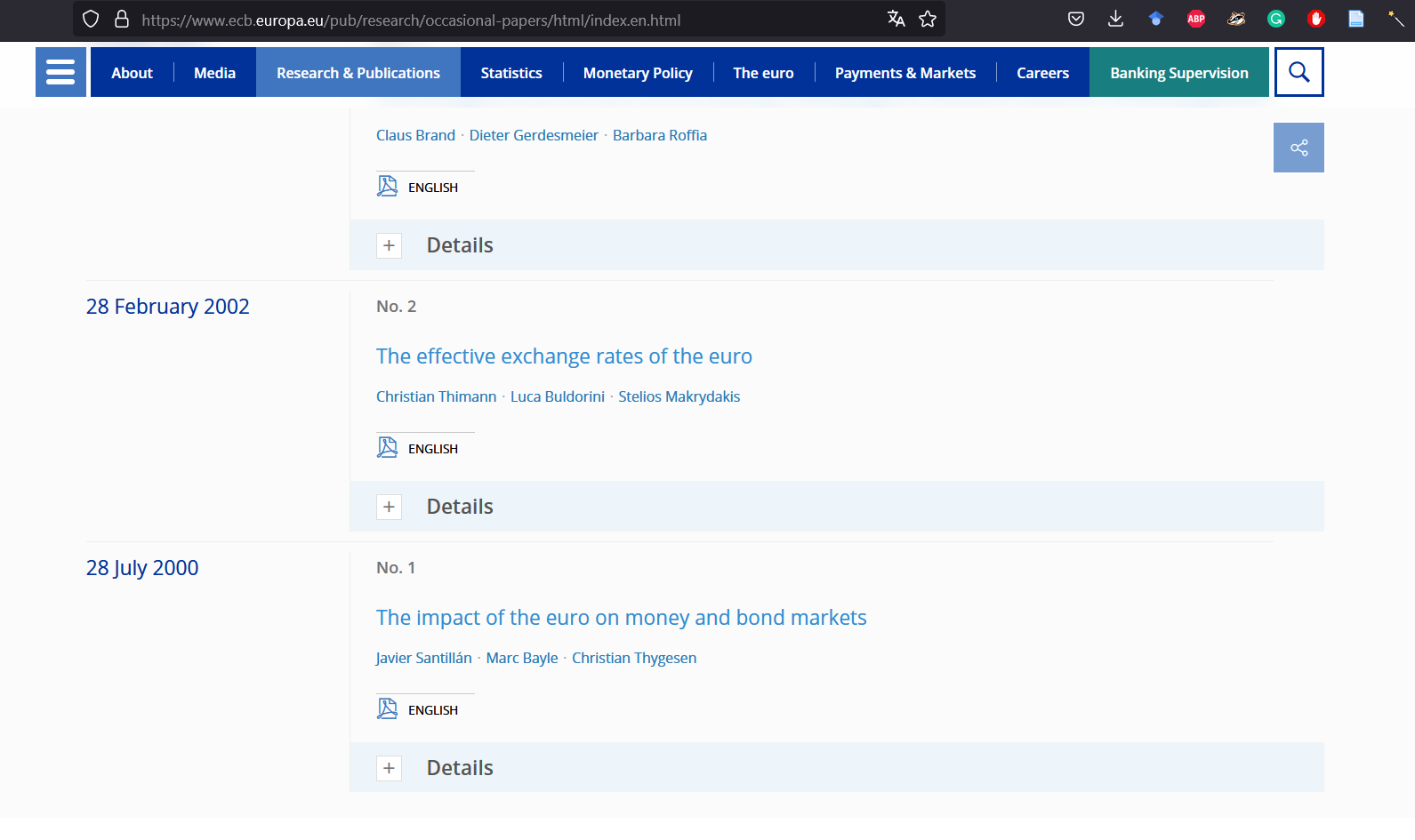
Figure 2: Les ‘occasional papers’ de la BCE
Fouillons un peu dans le code html de la page web. Dans Firefox, vous pouvez aller dans les “outils supplémentaires” et ouvrir les “outils de développement web”. Vous pouvez voir qu’il y a quelque chose appelé lazyload-container.
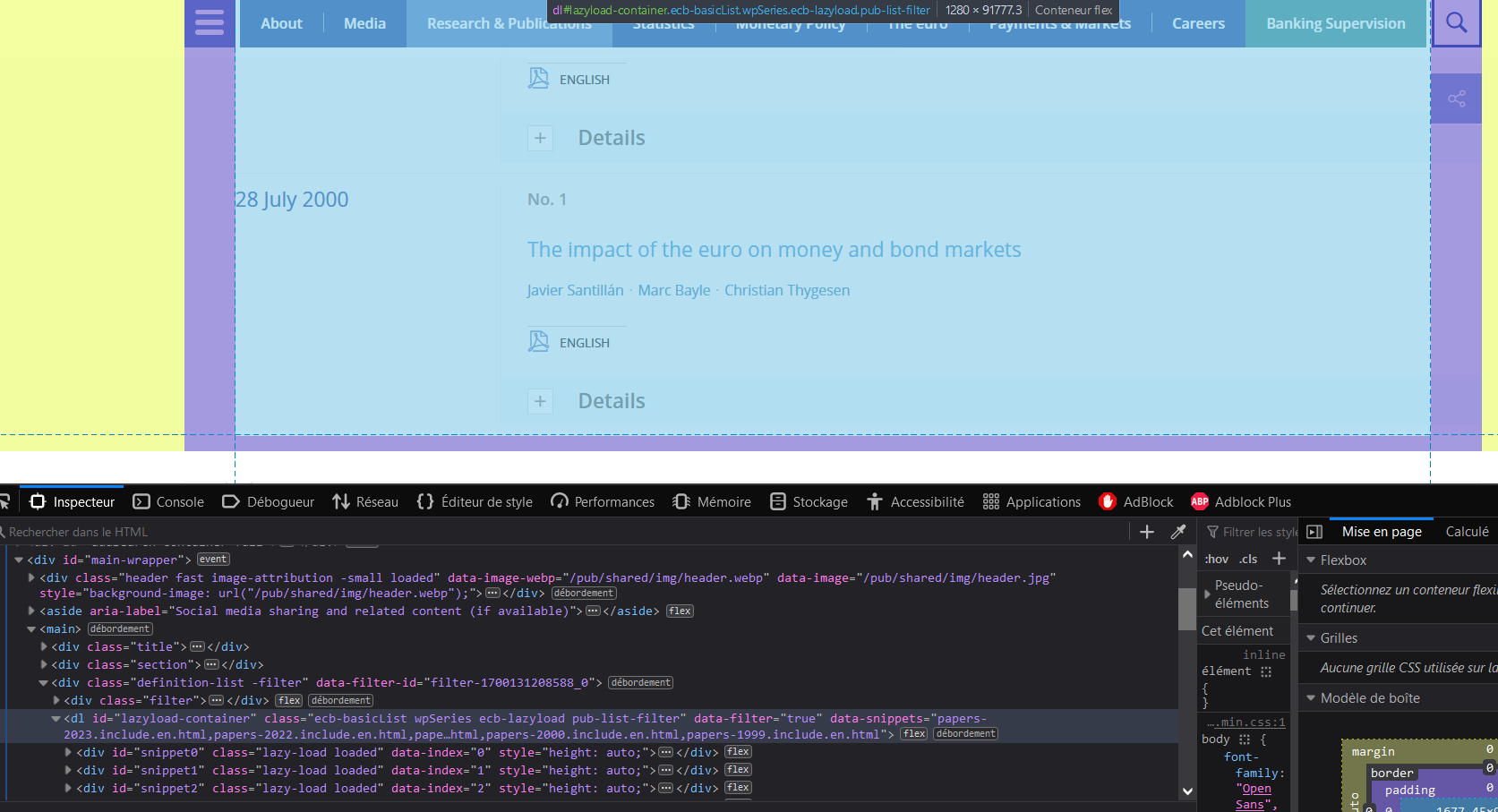
Figure 3: Le code source de la page web des occasional papers
Comme le nombre de documents occasionnels est assez élevé, pour des raisons d’efficacité, le site web ne charge pas l’ensemble des informations. Par conséquent, si vous souhaitez récupérer tous les articles, vous devez faire défiler la page vers le bas, et vous devez faire défiler progressivement pour être sûr que tous les conteneurs sont chargés. La fonction executeScript() de RSelenium vous permet d’utiliser du code JavaScript. Ici, on ne veut pas faire défiler horizontalement, mais verticalement : il faut donc définir le nombre de pixels dont on veut descendre (mettons 1600 pour être sûr de descendre lentement). Nous allons répéter cette opération un certain nombre de fois : comme faire défiler vers le bas de 1600 pixels équivaut à faire défiler vers le bas d’un peu plus de cinq papiers, nous divisons le nombre de papiers par 5, pour connaître le nombre d’itérations du mouvement de défilement vers le bas.
scroll_height <- 1600
scroll_iteration <- str_extract(categories[1], "\\d+") %>%
as.numeric()/5
for(i in 1:ceiling(scroll_iteration)) {
browser$executeScript(glue("window.scrollBy(0,{scroll_height});"))
Sys.sleep(0.3)
}
Vérifions que tous les documents de travail sont maintenant disponibles :
categories <- browser$findElements("css selector", ".category") %>%
map_chr(., ~.$getElementText()[[1]])
length(categories)
## [1] 298
Tout va bien. Mais nous sommes confrontés à un deuxième problème : certaines informations importantes ne sont pas encore visibles. En effet, il faut cliquer sur le bouton “Détails” pour accéder au résumé et aux codes JEL de l’article.
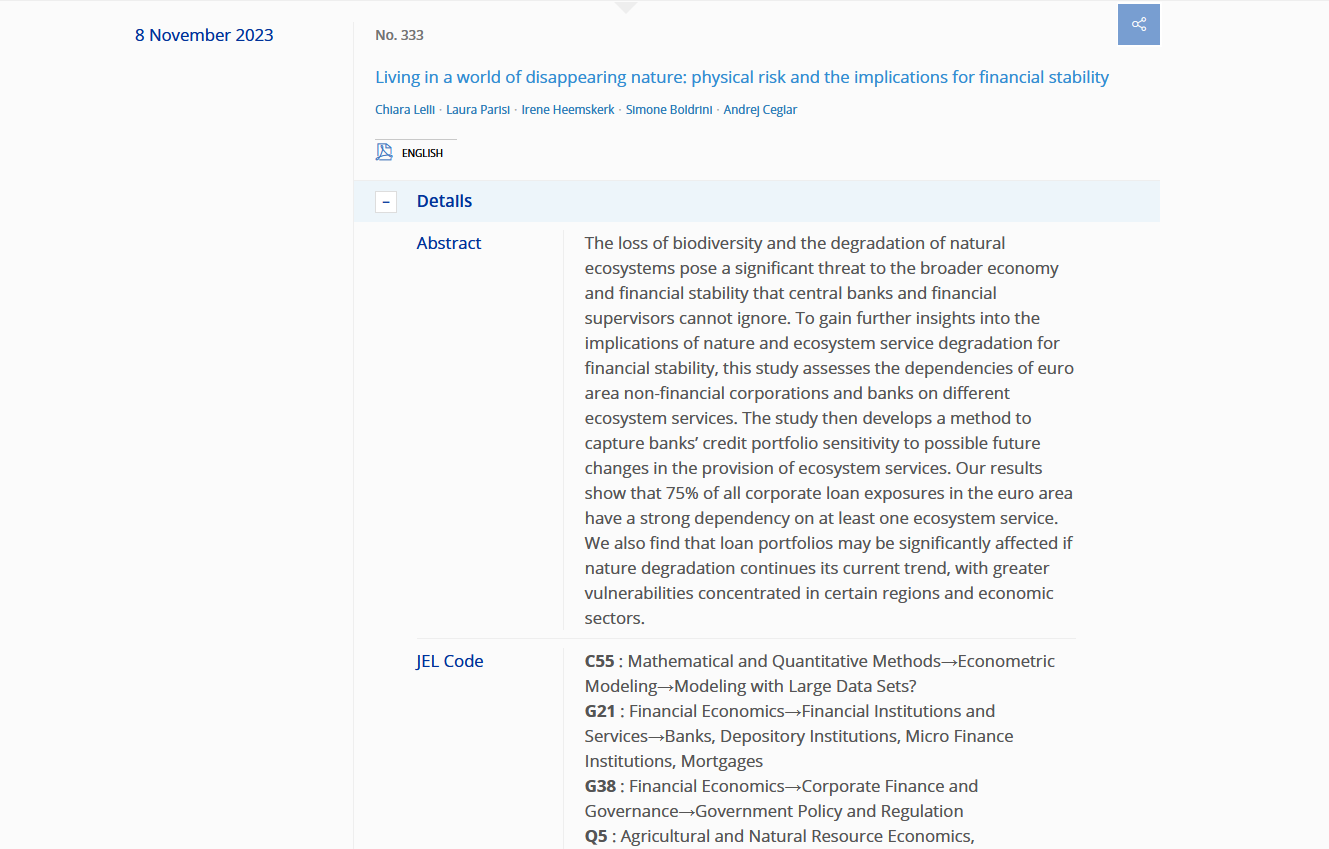
Figure 4: The ‘details’ menu
Mais tant que le menu Détails est fermé, l’information n’est pas accessible. Il faut donc trouver tous les boutons qui permettent de cliquer sur le menu “Détails”. Mais attention, nous ne voulons que le bouton “Détails”, et pas d’autres types de boutons. Comme dans le précédent billet, le module complémentaire Firefox ScrapeMate est indispensable pour trouver le bon sélecteur CSS.
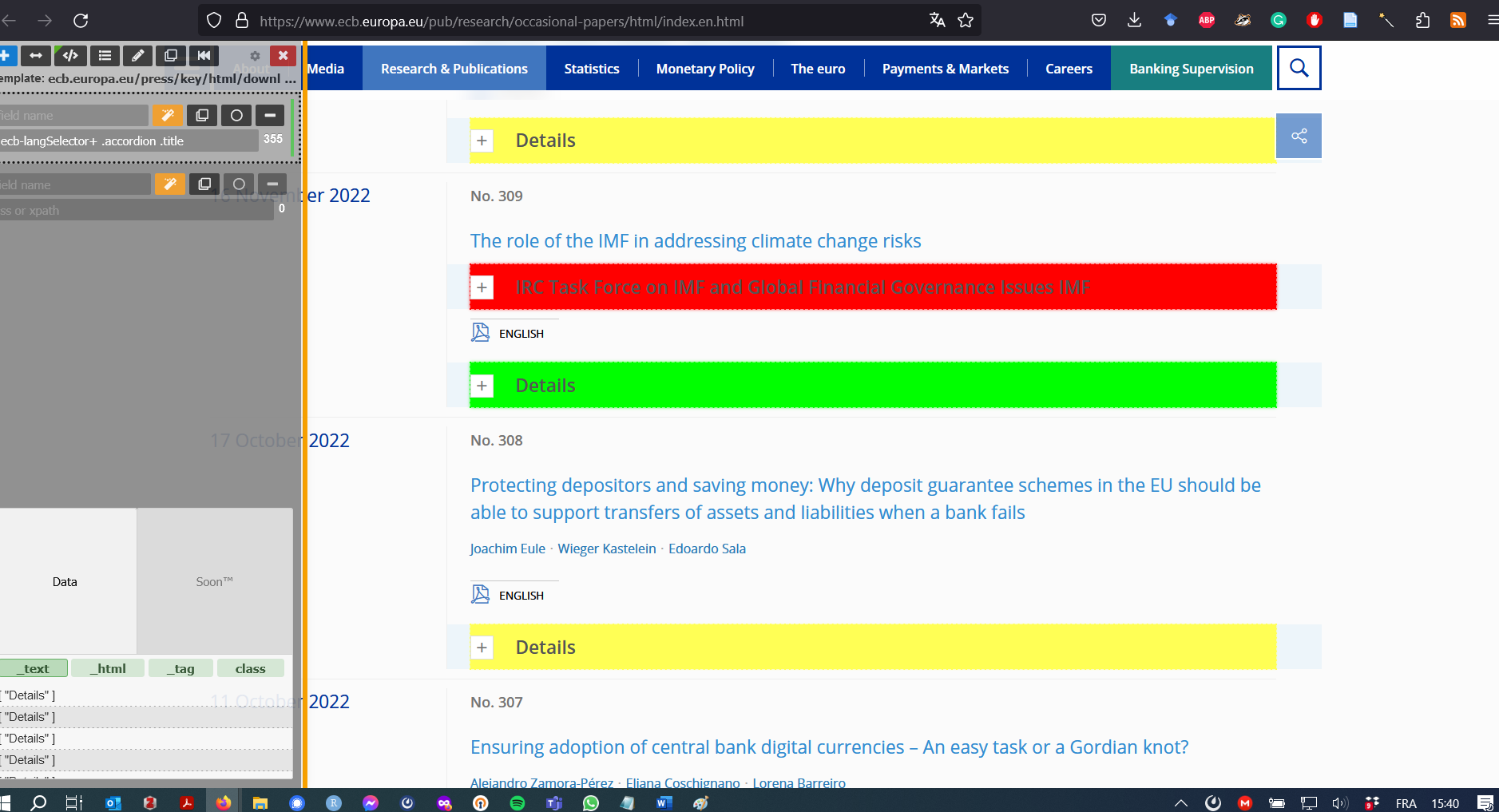
Figure 5: ScrapeMate Beta
Nous pouvons maintenant cliquer sur tous les boutons “Détails”, et uniquement sur les boutons “Détails” :
buttons <- browser$findElements("css selector", ".ecb-langSelector+ .accordion .header:nth-child(1) .title")
for(i in seq_along(buttons)){
buttons[[i]]$clickElement()
Sys.sleep(0.4)
}
Nous disposons désormais de toutes les informations qui nous intéressent. Le problème restant est que certaines informations peuvent être manquantes (ou inexistantes) pour certains documents (par exemple, un document n’a pas d’auteur). Nous extrayons donc les dates séparément, puis nous groupons l’ensemble des informations (hors date) pour chaque article dans l’objet papers_whole_information. De cet objet, nous extrayons tour à tour le titre, les auteurs, l’URL du pdf, et les informations en détail2.
papers_whole_information <- browser$getPageSource()[[1]] %>% # we extract the whole info of each paper here (without the date)
read_html() %>%
html_elements("dd")
metadata <- tibble(
category = categories,
dates = browser$findElements("css selector", ".loaded > dt") %>%
map_chr(., ~.$getElementText()[[1]]),
titles = papers_whole_information %>%
html_elements(".category+ .title a") %>%
html_text(),
authors = papers_whole_information %>%
html_elements("ul") %>%
html_text2(),
details = papers_whole_information %>%
html_elements(".ecb-langSelector+ .accordion .content-box:nth-child(2)") %>%
html_text2(),
url_pdf = papers_whole_information %>%
html_elements(".authors+ .ecb-langSelector .pdf") %>%
html_attr("href")
)
head(metadata)
## # A tibble: 6 × 6
## category dates titles authors details url_pdf
## <chr> <chr> <chr> <chr> <chr> <chr>
## 1 No. 333 8 November 2023 Living in a world of disap… "Chiar… "Abstr… /pub/p…
## 2 No. 332 24 October 2023 The effects of high inflat… "Krzys… "Abstr… /pub/p…
## 3 No. 331 17 October 2023 The future of DAOs in fina… "Ellen… "Abstr… /pub/p…
## 4 No. 330 16 October 2023 Inflation, fiscal policy a… "Henri… "Abstr… /pub/p…
## 5 No. 329 20 September 2023 How usable are capital buf… "Georg… "Abstr… /pub/p…
## 6 No. 317 13 September 2023 Recent advances in the lit… "Rolan… "Abstr… /pub/p…
Deux points à clarifier ici :
- le sélecteur CSS doit être choisi avec soin. Par exemple, un document peut avoir plusieurs
.title a, car il regroupe des documents complémentaires. Le document 209 en est un exemple. On ne veut donc que le titre après la catégorie. D’où le sélecteur.category+ .title a. C’est la même logique pour le menu “détails” : vous ne voulez pas ce qui se trouve dans “annexe” par exemple. De même, vous pouvez avoir plusieurs liens pdf, et vous ne voulez que le lien PDF sous les auteurs, qui est lien vers le PDF de l’article (et pas le lien vers le PDF d’un annexe technique). - les colonnes
authorsetdetailsdoivent encore être nettoyées. En effet, vous pouvez avoir plusieurs auteurs, et la colonnedetailsrassemble des informations sur le résumé et les codes JEL, mais aussi, en de rares occasions, la “Taxonomy” et le “Network”. C’est pourquoi nous utilisons la fonctionhtml_text2()de rvest : chaque type d’information est séparé par un saut de ligne (“\n”).
Nettoyons les détails. Vous séparez d’abord les lignes :
details_cleaned <- metadata %>%
select(category, details) %>%
separate_longer_delim(details, "\n") %>%
filter(! details == "")
head(details_cleaned, 20)
## # A tibble: 20 × 2
## category details
## <chr> <chr>
## 1 No. 333 Abstract
## 2 No. 333 The loss of biodiversity and the degradation of natural ecosystems …
## 3 No. 333 JEL Code
## 4 No. 333 C55 : Mathematical and Quantitative Methods→Econometric Modeling→Mo…
## 5 No. 333 G21 : Financial Economics→Financial Institutions and Services→Banks…
## 6 No. 333 G38 : Financial Economics→Corporate Finance and Governance→Governme…
## 7 No. 333 Q5 : Agricultural and Natural Resource Economics, Environmental and…
## 8 No. 332 Abstract
## 9 No. 332 The recent spike in inflation, unprecedented in the history of the …
## 10 No. 332 JEL Code
## 11 No. 332 C3 : Mathematical and Quantitative Methods→Multiple or Simultaneous…
## 12 No. 332 E3 : Macroeconomics and Monetary Economics→Prices, Business Fluctua…
## 13 No. 332 E6 : Macroeconomics and Monetary Economics→Macroeconomic Policy, Ma…
## 14 No. 331 Abstract
## 15 No. 331 Despite the crypto-market crash in the spring of 2022 and the colla…
## 16 No. 331 JEL Code
## 17 No. 331 F38 : International Economics→International Finance→International F…
## 18 No. 331 F39 : International Economics→International Finance→Other
## 19 No. 331 G23 : Financial Economics→Financial Institutions and Services→Non-b…
## 20 No. 331 G32 : Financial Economics→Corporate Finance and Governance→Financin…
Ce qu’il faut faire, c’est extraire la catégorie d’information (“Abstract|JEL Code|Taxonomy|Network”), et le texte ci-dessous représente le contenu de cette catégorie d’information. Vous pouvez ensuite faire pivoter les données pour remplir chaque colonne de l’article. Bien entendu, la plupart des colonnes relatives à la taxonomie et au réseau seront vides. Comme vous avez plusieurs codes JEL pour chaque article, pivot_wider() crée des colonnes sous forme de liste pour chaque type d’information. Mais vous pouvez transformer en chaîne de caractères les valeurs des colonnes avec des valeurs uniques (“Abstract”, “Taxonomy”, et “Network”).
details_cleaned <- details_cleaned %>%
mutate(type = str_extract(details, "^Abstract$|^JEL Code$|^Taxonomy$|^Network$")) %>%
fill(type, .direction = "down") %>% # we replace NA values in the type column by the information above which is non NA
filter(! str_detect(details, "^Abstract$|^JEL Code$|^Taxonomy$|^Network$")) %>% # we remove the title rows
pivot_wider(names_from = type, values_from = details) %>%
unnest(cols = c("Abstract", "Taxonomy", "Network"))
head(details_cleaned)
## # A tibble: 6 × 5
## category Abstract `JEL Code` Network Taxonomy
## <chr> <chr> <list> <chr> <chr>
## 1 No. 333 The loss of biodiversity and the degrada… <chr [4]> <NA> <NA>
## 2 No. 332 The recent spike in inflation, unprecede… <chr [3]> <NA> <NA>
## 3 No. 331 Despite the crypto-market crash in the s… <chr [7]> <NA> <NA>
## 4 No. 330 This paper analyses the distributional i… <chr [6]> <NA> <NA>
## 5 No. 329 This paper analyses banks’ ability to … <chr [2]> <NA> <NA>
## 6 No. 317 Large swings in cross-border capital flo… <chr [2]> <NA> <NA>
Regardons de plus prêt ce que contient la colonne JEL code :
head(details_cleaned %>% select(category, `JEL Code`) %>% unnest(`JEL Code`))
## # A tibble: 6 × 2
## category `JEL Code`
## <chr> <chr>
## 1 No. 333 C55 : Mathematical and Quantitative Methods→Econometric Modeling→Mod…
## 2 No. 333 G21 : Financial Economics→Financial Institutions and Services→Banks,…
## 3 No. 333 G38 : Financial Economics→Corporate Finance and Governance→Governmen…
## 4 No. 333 Q5 : Agricultural and Natural Resource Economics, Environmental and …
## 5 No. 332 C3 : Mathematical and Quantitative Methods→Multiple or Simultaneous …
## 6 No. 332 E3 : Macroeconomics and Monetary Economics→Prices, Business Fluctuat…
Enfin, il suffit de fusionner les détails nettoyés avec les métadonnées :
metadata_cleaned <- metadata %>%
select(-details) %>%
left_join(details_cleaned)
head(metadata_cleaned)
## # A tibble: 6 × 9
## category dates titles authors url_pdf Abstract `JEL Code` Network Taxonomy
## <chr> <chr> <chr> <chr> <chr> <chr> <list> <chr> <chr>
## 1 No. 333 8 Novemb… Livin… "Chiar… /pub/p… The los… <chr [4]> <NA> <NA>
## 2 No. 332 24 Octob… The e… "Krzys… /pub/p… The rec… <chr [3]> <NA> <NA>
## 3 No. 331 17 Octob… The f… "Ellen… /pub/p… Despite… <chr [7]> <NA> <NA>
## 4 No. 330 16 Octob… Infla… "Henri… /pub/p… This pa… <chr [6]> <NA> <NA>
## 5 No. 329 20 Septe… How u… "Georg… /pub/p… This pa… <chr [2]> <NA> <NA>
## 6 No. 317 13 Septe… Recen… "Rolan… /pub/p… Large s… <chr [2]> <NA> <NA>
Et vous avez maintenant une table de métadonnées pour les documents occasionnels de la BCE ! Le post sur la BRI explique ensuite comment télécharger le PDF, et comment exécuter l’OCR si le texte des PDFs n’est pas reconnu. Le code de ce post-ci fonctionne également pour les “discussion papers” et “working papers” de la BCE.
Une autre méthode
Vous pouvez utiliser la méthode ci-dessus pour récupérer les métadonnées de près de 3000 documents de travail de la BCE. Mais vous pouvez imaginer qu’il faut beaucoup de temps pour faire défiler la page, et surtout pour ouvrir tous les menus “Détails”. RSelenium est merveilleusement utile pour interagir avec le navigateur web, mais parfois, en creusant dans le code source d’une page web, vous pouvez trouver des moyens plus faciles d’extraire des informations pertinentes.
C’est le cas pour les pages de recherche de la BCE. Nous avons déjà croisé un indice à ce sujet dans ce billet. En effet, regardons à nouveau le code relatif au “lazyload-container”.
Figure 6: Digging into ECB’s website code
En fait, il nous indique que le site web charge d’autres pages, qui se terminent par “papers-2023.include.en.html”, “papers-2022.include.en.html”, etc., jusqu’à “papers-1999.include.en.html”. Essayons la première : “https://www.ecb.europa.eu/pub/research/working-papers/html/papers-2023.include.en.html”
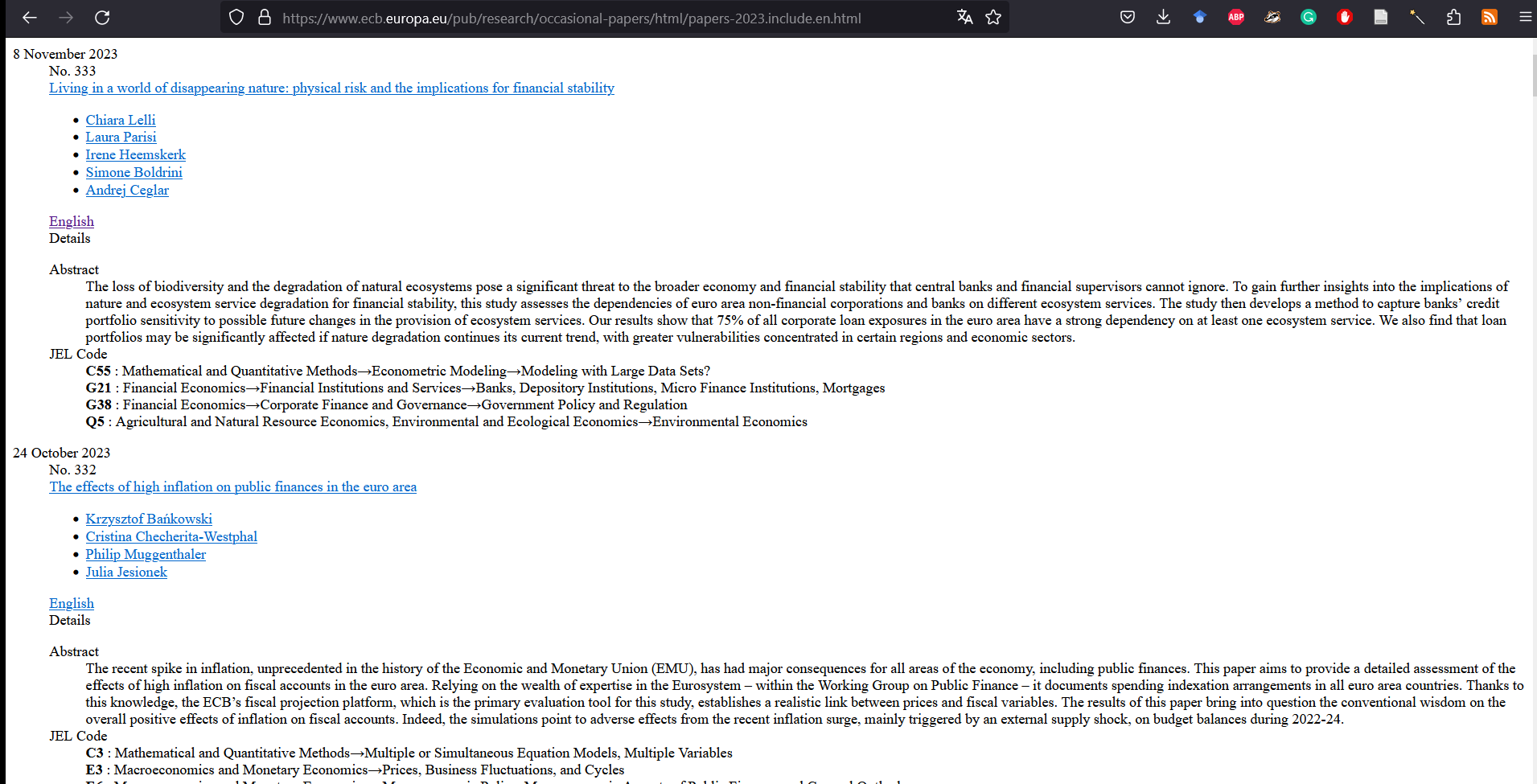
Figure 7: A simpler ECB page
Nous pouvons donc moissonner assez facilement les occasional papers pour 2023 :
url <- "https://www.ecb.europa.eu/pub/research/occasional-papers/html/papers-2023.include.en.html"
html_info <- read_html(url) %>%
html_elements(xpath = "/html/body/dd")
metadata <- tibble(
category = html_info %>%
html_elements(".category") %>%
html_text(),
dates = read_html(url) %>%
html_elements(".date") %>%
html_text(),
titles = html_info %>%
html_elements(".category+ .title a") %>%
html_text(),
authors = html_info %>%
html_elements("ul") %>%
html_text2(),
details = html_info %>%
html_elements(".ecb-langSelector+ .accordion .content-box:nth-child(2)") %>%
html_text2(),
url_pdf = html_info %>%
html_elements(".pdf") %>%
html_attr("href")
)
head(metadata)
Bibliographie
Harrison, John. 2022. RSelenium: R Bindings for ’Selenium WebDriver’. https://CRAN.R-project.org/package=RSelenium.
Perepolkin, Dmytro. 2023. Polite: Be Nice on the Web. https://CRAN.R-project.org/package=polite.
Wickham, Hadley. 2022. Rvest: Easily Harvest (Scrape) Web Pages. https://CRAN.R-project.org/package=rvest.
Aurélien Goutsmedt
Chercheur Postdoctoral et Chargé de Cours
Je travaille sur l’histoire de l’économie et l’expertise économique.