Scraping Central Bankers' Speeches from the BIS Website
Scraping Tutorials 1
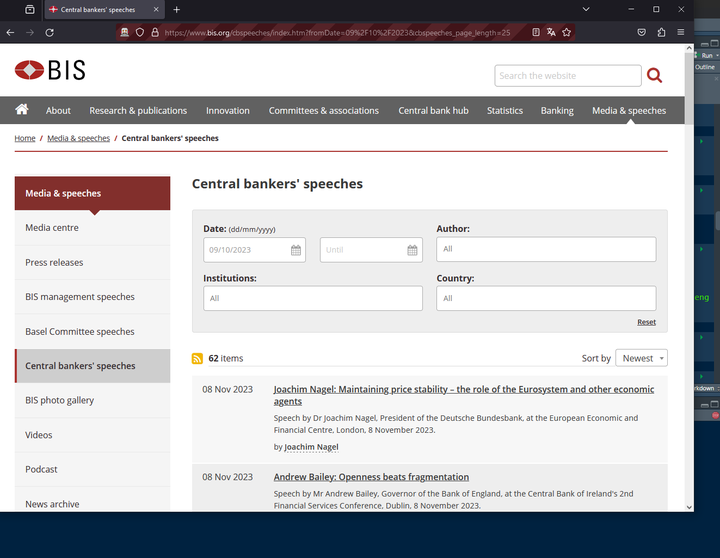
Table of Contents
Scraping data
In this post, you will learn how to scrape speeches from the Bank of International Settlements database of speeches, which gathers most of central bankers’ speeches in English. We will do it programming in R. The second tutorial focuses on scraping documents from the European Central Bank website and the third one scrape the Bank of England’s website.
Before going along the scraping, let’s start by a general introduction about what web scraping is.
What is web scraping?
Web scraping is the process of extracting data from websites. It involves programmatically accessing a website’s content, extracting the data you want, and then saving it for further use. It involves going to a specific URL, retrieving the html content and extract the data you want from this content.
In general, you need to use web scraping when there is no API (Application Programming Interface) for the website data you want to access. An API is a structured and authorized way to access data provided by a website, from a system of queries (for instance, scopus provides an API to retrieve its bibliometric data).
Scraping data on a website implies various ethical and legal issues (for which I am not a specialist at all!). First, many websites have terms of service agreements that explicitly prohibit web scraping. Engaging in scraping without the website owner’s consent violates these terms and conditions. For instance, Linkedin prohibits scraping on its website. However, the “legality” of scraping Linkedin remains a complex matter. Before engaging in scraping, you need to know what are the terms and conditions, and know what are the risks if you violate them.
A second issue has to do with overloading servers. Web scraping can put a significant load on a website’s servers, potentially leading to decreased performance or downtime. Scraping without proper rate limiting and respect for a website’s capacity can be seen as unethical and disruptive.
Third, if you may be allowed to scrape a website, it does not mean that you can copy and distribute the materials collected. You should be aware of copyright laws and intellectual property rights when diffusing scraped content.
Some useful resources
When talking about web scraping with R, three R packages stand out (but we will only use two of them here):
- rvest (Wickham 2022): a package in the tidyverse spirit that helps to extract data from web pages. It works better with static web page (see below).
- RSelenium (Harrison 2022): this is an R binding for Selenium 2.0 Remote WebDriver, which allows you to automate the use of a browser. In other words, it enables you to write a script to open a web browser and interact with a website (yes, this is where scraping starts to get fun).
- polite (Perepolkin 2023): this package allows you to look at the robots.txt of a website to know what are the scraping rules for this website, and to avoid hammering the site with too many requests.
Depending on the website you want to scrap, using rvest may be sufficient (as it is the case, for instance, with Wikipedia). For more complicated website, you may need RSelenium, in combination with rvest or alone. Indeed, it depends if the web pages you want to scrape are static or dynamic web pages. As explained by Ivan Milanes’ useful blog post:
- Static Web Page: A Web page (HTML page) that contains the same information for all users. Although it may be periodically updated from time to time, it does not change with each user retrieval.
- Dynamic Web Page: A Web page that provides custom content for the user based on the results of a search or some other request. Also known as “dynamic HTML” or “dynamic content”, the “dynamic” term is used when referring to interactive Web pages created for each user.
The web page where central bankers’ speeches are gathered is a dynamic web page and so we will use RSelenium to scrape the speeches.1
To complement this tutorial, you will find two other useful tutorials for scraping using rvest and RSelenium here and here. There is also a whole chapter dedicated to web scraping in the recent second edition of R for Data Science (Wickham, Çetinkaya-Rundel, and Grolemund 2023).
Scraping the BIS speeches
If we are interested in what central bankers are saying, we may want to study their speeches. Fortunately, most of them are stored on the BIS website there.
Figure 1: The BIS list of speeches
What we want is
- to extract the metadata of these speeches: the date of the speech, the title, its description and the speaker.
- to access to the whole text of the speech, that is stored in a pdf on the BIS website
- to extract the text from this PDF
- to be sure that the text is readable, which will be the case if the PDF is searchable (i.e. if characters are recognized).
This is all these things we will learn to do in this tutorial.
Loading the packages and starting your automated browser
We first load the necessary packages. RSelenium (Harrison 2022) and polite are the central packages here. I like the here package to manipulate paths with R but it is not essential here… glue is used to create strings more easily, by embedding R expressions in it. pdftools will be used to extract text from the speeches’ PDFs and tesseract for running Optical Character Recognition (OCR) on PDFs that don’t have a good OCR.
# pacman is a useful package to install missing packages and load them
if(! "pacman" %in% installed.packages()){
install.packages("pacman", dependencies = TRUE)
}
pacman::p_load(tidyverse,
RSelenium,
polite,
glue,
here,
pdftools,
tesseract)
bis_data_path <- here(path.expand("~"), "data", "central_bank_database", "BIS") # Where data will go on my computer
Going on the BIS website and launching the bot
We use polite to “bow” in front of the BIS website. It allows us to look at permissions for scraping.
bis_website_path <- "https://www.bis.org/"
session <- bow(bis_website_path)
session
## <polite session> https://www.bis.org/
## User-agent: polite R package
## robots.txt: 15 rules are defined for 2 bots
## Crawl delay: 5 sec
## The path is scrapable for this user-agent
By looking at the robots.txt file, we can see more in details which paths of the website are scrapable or not.
cat(session$robotstxt$text)
## #Format is:
## # User-agent: <name of spider>
## # Disallow: <nothing> | <path>
## #-------------------------------------------
##
## User-Agent: *
## Disallow: /dcms
## Disallow: /metrics/
## Disallow: /search/
## Disallow: /staff.htm
## Disallow: /embargo/
## Disallow: /app/
## Disallow: /goto.htm
## Disallow: /login
## #Disallow: /cbhub
## Disallow: /cbhub/goto.htm
## Disallow: /doclist/
## # Committee comment letters
## Disallow: /publ/bcbs*/
## Disallow: /bcbs/ca/
## Disallow: /bcbs/commentletters/
## Disallow: /*/publ/comments/
## # Hide the Basel Framework standards, only chapters should be indexed.
## Disallow: /basel_framework/standard/
##
## Sitemap: https://www.bis.org/sitemap.xml
The list of speeches is at “https://www.bis.org/cbspeeches/index.htm”. This path is not among the “disallow” list, meaning that we can scrape this part of the website.
We want to make scraping easier, so we will display the maximum number of items per page, which is 25 here. We don’t want to scrape the whole list of speeches, so we will set a starting date: the ninth of October, 2023. By navigating towards the second page of the resulting list, you can now have an idea of what the URL looks like.
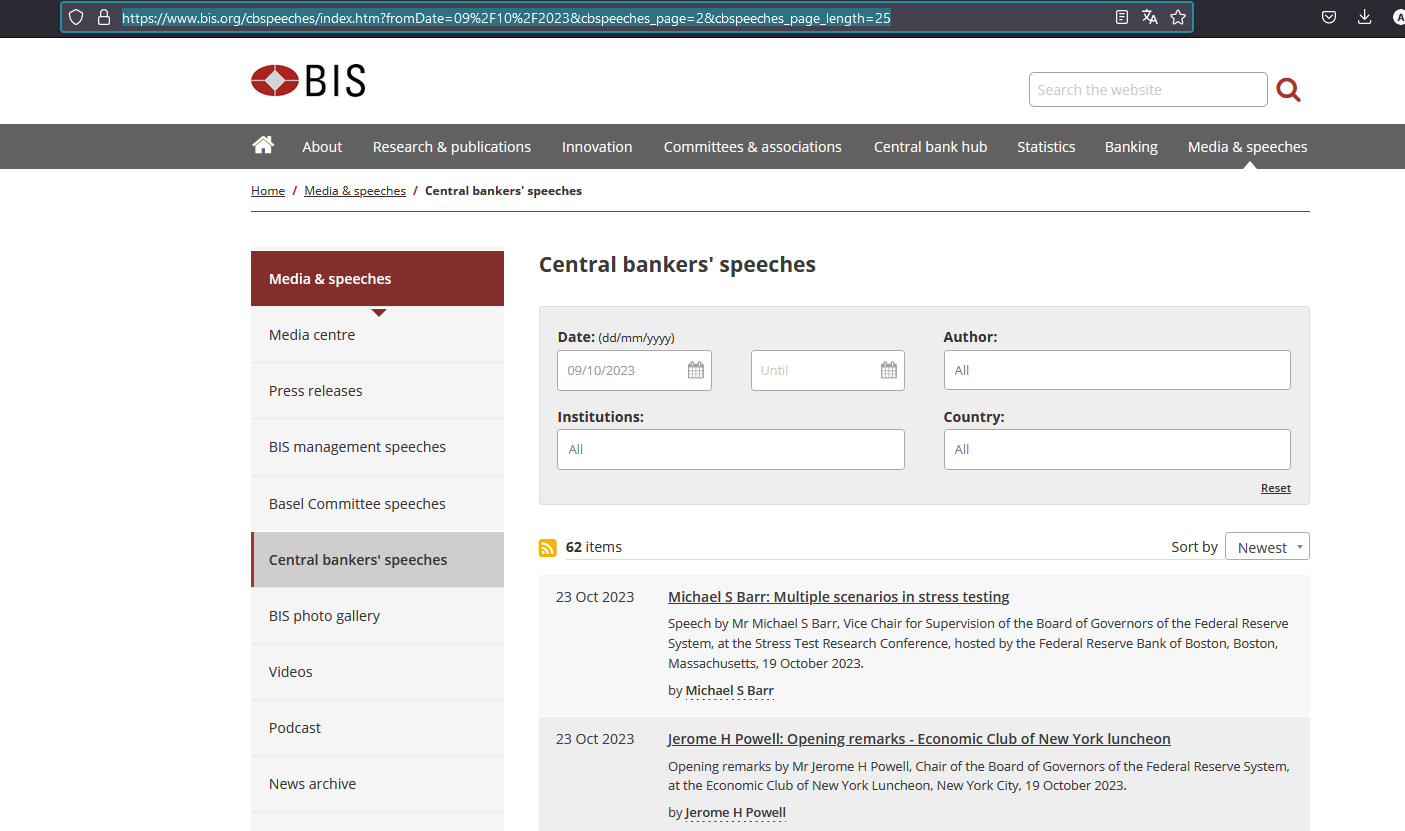
Figure 2: Filtering speeches on the BIS website
Thus, you can prepare a string with the URL to scrape, in which you can change the parameters.
scraping_path <- expr(glue("{bis_website_path}cbspeeches/index.htm?fromDate={day}%2F{month}%2F{year}&cbspeeches_page={page}&cbspeeches_page_length=25"))
Here, I could have used some simpler programming by using the paste0() function for instance, rather than using expr(). But I want to be able to change the parameters later, notably for the page number. For now, the path looks like this:
scraping_path
## glue("{bis_website_path}cbspeeches/index.htm?fromDate={day}%2F{month}%2F{year}&cbspeeches_page={page}&cbspeeches_page_length=25")
But then I can enter the parameters I want for the date (here, the ninth of October, 2023).
day <- "09"
month <- "10"
year <- 2023
And I can evaluate the expression with these parameters, also selecting a certain page. This will be useful later in a loop to navigate from one page to the next.
eval(scraping_path, envir = list(page = 3))
## https://www.bis.org/cbspeeches/index.htm?fromDate=09%2F10%2F2023&cbspeeches_page=3&cbspeeches_page_length=25
You can check that this URL leads you to the third page of the list of speeches starting the ninth of October, 2023 (with 25 results per page).
Once you have the structure of the URL, it means that you can change the parameters as you want to create the list of speeches you want. Of course, you can go on the BIS website and filter by the end date or the “Institutions” or the “Country” to see what the URL would look like.
Now we can start the funny part. Let’s launch our automated browser with RSelenium:
# Launch Selenium to go on the website of bis
driver <- rsDriver(browser = "firefox", # can also be "chrome"
chromever = NULL,
port = 4444L)
remote_driver <- driver[["client"]]
Figure 3: Automatizing your web browser
Extracting the data page by page
What we want to do is to retrieve the data about each speech (the date, the title, its description, the speaker, and also its corresponding URL) page by page. This is something that we can do with a for loop. But we first need to know the number of pages. You can normally see it at the bottom right of the web page.
There could be different way to extract this information. Here, we will use the “CSS selector”. Using the CSS selector has two advantages:
- It has in general a simpler content than an XPATH
- It can be easily retrieved thanks to a Firefox add-on (which exists also for Chrome): ScrapeMate
Once you have set up the add-on, you can go to the URL we are working on and find the “CSS selector” for the number of pages:
Figure 4: Using scrapemate Firefox addon
You can use this CSS selector to extract the text thanks to RSelenium and after a short cleaning, you have the total number of pages:
remote_driver$navigate(eval(scraping_path, envir = list(page = 1)))
Sys.sleep(2) # Just to have time to load the page
nb_pages <- remote_driver$findElement("css selector", ".pageof")$getElementText() %>% # We just set i for searching the total number of pages
pluck(1) %>%
str_remove_all("Page 1 of ") %>%
as.integer()
nb_pages
## [1] 6
Ok. Now we can run the loop to retrieve all the data for the 6 pages. Here, we will conform to the delay set by the polite package: we will wait 5 seconds on each page, not to hammer the website with too many requests. As we need the web page to load properly to retrieve the data, it is also a way to take the time of loading the page to avoid missing data if your internet connection is too slow.
Here, you just have to use scrapemate to find the appropriate CSS selector for each information and extract the corresponding text. You can also see that by clicking on the title of the speech, you are navigating towards the dedicated web page of the corresponding speech. It means that to the title is associated a URL link, a “href” in html language. So you need to extract the “href” attribute associated to the title thanks to RSelenium.
metadata <- vector(mode = "list", length = nb_pages)
for(page in 1:nb_pages){
remote_driver$navigate(eval(scraping_path))
nod <- nod(session, eval(scraping_path)) # introducing to the new page
Sys.sleep(session$delay) # using the delay time set by polite
metadata[[page]] <- tibble(date = remote_driver$findElements("css selector", ".item_date") %>%
map_chr(., ~.$getElementText()[[1]]),
info = remote_driver$findElements("css selector", ".item_date+ td") %>%
map_chr(., ~.$getElementText()[[1]]),
url = remote_driver$findElements("css selector", ".dark") %>%
map_chr(., ~.$getElementAttribute("href")[[1]]))
}
metadata <- bind_rows(metadata) %>%
separate(info, c("title", "description", "speaker"), "\n")
head(metadata)
## # A tibble: 6 × 5
## date title description speaker url
## <chr> <chr> <chr> <chr> <chr>
## 1 27 Nov 2023 "Ahmet Ismaili: Welcoming remarks - Wor… "Welcoming… by Ahm… http…
## 2 27 Nov 2023 "Ahmet Ismaili: Creating values – a gat… "Introduct… by Ahm… http…
## 3 22 Nov 2023 "Christine Lagarde: Monetary policy in … "Speech by… by Chr… http…
## 4 22 Nov 2023 "Sabine Mauderer: Exposing and acting o… "Speech by… by Sab… http…
## 5 21 Nov 2023 "Jon Cunliffe: Money and payments - a \… "Speech by… by Jon… http…
## 6 21 Nov 2023 "Shaktikanta Das: Emerging India - a la… "Keynote s… by Sha… http…
The findElements() function of RSelenium finds all the corresponding elements (here 25) and stores them in a list. The map_chr() allows you to get the text of each element one by one and stores the result in a vector.
If we want to be sure that we have retrieved the data of all the speeches, we can compare the length of our data frame, with the number of items that was indicated just above the first speech.
# We just check that we have the correct number of speeches
nb_items <- remote_driver$findElement("css selector", ".listitems")$getElementText() %>% # We just set i for searching the total number of pages
pluck(1) %>%
str_remove_all("[\\sitems]") %>%
as.integer()
if(nb_items == nrow(metadata)){
cat("You have extracted the metadata of all speeches")
} else{
cat("There is a problem. You have probably missed some speeches.")
}
## You have extracted the metadata of all speeches
Downloading the PDF
Now we have the metadata of the speeches. But one thing we are interested in at the end is to know what the speeches are about. Most of the speeches are stored in a pdf. To retrieve these PDFs, you just need to use the URL of the speech, and replace the end of the URL “.htm” by “.pdf”. From the metadata list, we can have the whole list of the PDFs we want to download.
pdf_to_download <- metadata %>%
mutate(pdf_name = str_extract(url, "r\\d{6}[a-z]"),
pdf_name = str_c(pdf_name, ".pdf")) %>%
pull(pdf_name)
pdf_to_download
## [1] "r231127c.pdf" "r231127d.pdf" "r231122b.pdf" "r231122a.pdf" "r231121a.pdf"
## [6] "r231115e.pdf" "r231121i.pdf" "r231121h.pdf" "r231121g.pdf" "r231121f.pdf"
## [11] "r231121e.pdf" "r231121d.pdf" "r231121c.pdf" "r231121b.pdf" "r231120j.pdf"
## [16] "r231120h.pdf" "r231120i.pdf" "r231114a.pdf" "r231114b.pdf" "r231115r.pdf"
## [21] "r231115s.pdf" "r231114c.pdf" "r231115t.pdf" "r231115u.pdf" "r231120g.pdf"
## [26] "r231120f.pdf" "r231120e.pdf" "r231120d.pdf" "r231120c.pdf" "r231120b.pdf"
## [31] "r231120a.pdf" "r231113s.pdf" "r231115q.pdf" "r231115o.pdf" "r231115n.pdf"
## [36] "r231115m.pdf" "r231115j.pdf" "r231115i.pdf" "r231115f.pdf" "r231115h.pdf"
## [41] "r231115g.pdf" "r231114d.pdf" "r231115d.pdf" "r231115p.pdf" "r231113n.pdf"
## [46] "r231115a.pdf" "r231113m.pdf" "r231115c.pdf" "r231114e.pdf" "r231114f.pdf"
## [51] "r231113t.pdf" "r231113o.pdf" "r231113q.pdf" "r231113x.pdf" "r231113w.pdf"
## [56] "r231113v.pdf" "r231113u.pdf" "r231113p.pdf" "r231113r.pdf" "r231113k.pdf"
## [61] "r231113j.pdf" "r231113i.pdf" "r231113h.pdf" "r231113g.pdf" "r231113f.pdf"
## [66] "r231113e.pdf" "r231113d.pdf" "r231113c.pdf" "r231113b.pdf" "r231113l.pdf"
## [71] "r231113a.pdf" "r231110a.pdf" "r231108c.pdf" "r231108b.pdf" "r231108a.pdf"
## [76] "r231107c.pdf" "r231107b.pdf" "r231107a.pdf" "r231102a.pdf" "r231027b.pdf"
## [81] "r231115l.pdf" "r231026l.pdf" "r231026j.pdf" "r231026q.pdf" "r231026g.pdf"
## [86] "r231026f.pdf" "r231026e.pdf" "r231026m.pdf" "r231026d.pdf" "r231026c.pdf"
## [91] "r231026b.pdf" "r231026a.pdf" "r231023h.pdf" "r231023g.pdf" "r231023e.pdf"
## [96] "r231023c.pdf" "r231023b.pdf" "r231023a.pdf" "r231020f.pdf" "r231020e.pdf"
## [101] "r231020d.pdf" "r231020c.pdf" "r231020b.pdf" "r231020a.pdf" "r231019g.pdf"
## [106] "r231019e.pdf" "r231019d.pdf" "r231019c.pdf" "r231019b.pdf" "r231019a.pdf"
## [111] "r231018f.pdf" "r231018e.pdf" "r231018d.pdf" "r231018c.pdf" "r231018b.pdf"
## [116] "r231018a.pdf" "r231017e.pdf" "r231017d.pdf" "r231017c.pdf" "r231017b.pdf"
## [121] "r231012a.pdf" "r231017a.pdf" "r231011d.pdf" "r231012b.pdf" "r231011g.pdf"
## [126] "r231011f.pdf" "r231011e.pdf" "r231011a.pdf" "r231011b.pdf" "r231010h.pdf"
## [131] "r231010g.pdf" "r231010f.pdf" "r231010e.pdf" "r231010d.pdf" "r231010c.pdf"
## [136] "r231010b.pdf" "r231010a.pdf" "r231115v.pdf"
We build a function to download these PDF using polite. It would avoid notably to overload the website.
polite_download <- function(domain, url, ...){
bow(domain) %>%
nod(glue(url)) %>%
rip(...)
}
There is a possibility that some PDFs are missing (that is not the case here, but it happens with the whole dataset of BIS speeches). The problem is that if a PDF is missing, you will get an error and it will stop the process of downloading PDFs So you need to use the tryCatch() function to take into account this error but continue the downloading process.
tryCatch(
{
walk(pdf_to_download, ~polite_download(domain = bis_website_path,
url = glue("review/{.}"),
path = here(bis_data_path, "pdf"),))
},
error = function(e) {
print(glue("No pdf exist"))
}
)
Here, the pdf has been stored in a specific repository on my computer, indicated by the parameter path.
Extracting speeches text
Now that we have collected the PDFs, we want to extract the text within these PDFs. We will use the package pdftools for that. Here is a function that take the list of PDFs extracted from the metadata, extract the text, and stores it in a table with the name of the file and the corresponding page of the text (indeed, pdf_text() extract the text page by page). Here, we handle error in case we did not find the PDF: we don’t want the extraction of text to stop, but we want to remember that a PDF is missing.
extracting_text <- function(file, path) {
tryCatch(
{
message(glue("Extracting text from {file}"))
text_data <- pdf_text(here(path, file)) %>%
as_tibble() %>%
mutate(page = 1:n(),
file = file) %>%
rename(text = value)
},
error = function(e) {
print(glue("No pdf exist"))
text_data <- tibble(text = NA,
page = 1,
file = file)
}
)
}
We can run the function for each speech we have in our dataset.
text_data <- map(pdf_to_download, ~extracting_text(., here(bis_data_path, "pdf"))) %>%
bind_rows()
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
head(text_data)
## # A tibble: 6 × 3
## text page file
## <chr> <dbl> <chr>
## 1 "Ahmet Ismaili: Welcoming remarks - World Savings Day\nWelcoming … 1 r231…
## 2 "Young people should set clear financial goals for themselves and… 2 r231…
## 3 "Ahmet Ismaili: Creating values – a gateway for the future\nIntro… 1 r231…
## 4 "Therefore, in CBK's supervisory role, the external auditor profe… 2 r231…
## 5 "3/3 BIS - Central bankers' speeches\n" 3 r231…
## 6 "Christine Lagarde: Monetary policy in the euro area - attentive … 1 r231…
Managing OCR problems
Sometimes, PDFs have problems of OCR. The PDFs are no searchable and so the text cannot be extracted properly (or rather, it is unreadable). It happens also with recent speeches. Therefore, we need to find the PDFs that may encounter such problems. We count the number of words in each page, and retrieve the PDFs for which the number of words is low in each page.
pdf_without_ocr <- text_data %>%
mutate(test_ocr = str_count(text, "[a-z]+")) %>% # Count the number of words
mutate(non_ocr_document = all(test_ocr < 250), .by = file) %>%
filter(non_ocr_document == TRUE) %>%
distinct(file) %>%
pull()
pdf_without_ocr
## [1] "r231122a.pdf" "r231121h.pdf" "r231121g.pdf" "r231121d.pdf" "r231110a.pdf"
## [6] "r231026f.pdf" "r231026c.pdf" "r231023h.pdf" "r231023g.pdf" "r231017d.pdf"
## [11] "r231017b.pdf" "r231011g.pdf" "r231010g.pdf" "r231010e.pdf" "r231010d.pdf"
## [16] "r231010c.pdf" "r231010b.pdf"
Setting the threshold at 250 words is a pure rule of thumb: it allows having only true positive, but it does not prevent for having false negative (missing documents with OCR problem). It should be possible to find a better method to assess which PDF have no OCR.
Here is an example of a problematic PDF:
text_data %>%
filter(file %in% pdf_without_ocr[1])
## # A tibble: 6 × 3
## text page file
## <chr> <dbl> <chr>
## 1 "012345637839 \u0011 3 7839843 \u0011\u000e433\u000f\u00103783984… 1 r231…
## 2 "01ÿ34567567ÿ85996ÿ45 ÿ\u000e\u000fÿ56\u000fÿ\u000f8ÿ\u00106ÿ\u00… 2 r231…
## 3 "0123456ÿ89252 49ÿ2 8ÿ\u000e8ÿ\u000f2ÿ94\u0010\u000f8ÿ9\u0011\u00… 3 r231…
## 4 "01ÿ3456ÿ17389ÿ83ÿ 8ÿ454543ÿ348ÿ57188\u000e51 ÿ\u000f7\u000e\u001… 4 r231…
## 5 "0123ÿ56ÿ718ÿ319\n ÿ\u000e\u000f9\u00103\u00112\u0012ÿ\u0013… 5 r231…
## 6 "0ÿ2345678934\n \u000e\u000fÿ\u0011 ÿ\u0012\u000e\u0011\u0013\… 6 r231…
It seems ok when you look at it, but going to the web page allows us to see that there are some problem of selection in the text and so that the OCR is not adequate.

Figure 5: PDF without adequate OCR
We will now use the tesseract package, that runs OCR. It first converts each page of the PDF into a picture (a PNG), then proceeds to OCR and extracts the text.
new_text_ocr <- vector(mode = "list", length = length(pdf_without_ocr))
for(i in 1:length(pdf_without_ocr)){
text <- tesseract::ocr(here(bis_data_path, "pdf", pdf_without_ocr[i]), engine = tesseract::tesseract("eng"))
text <- tibble(text) %>%
mutate(text = str_remove(text, ".+(=?\\\n)"),
page = 1:n(),
file = str_remove(pdf_without_ocr[i], "\\.pdf"))
new_text_ocr[[i]] <- text
}
new_text_ocr <- bind_rows(new_text_ocr)
## Converting page 1 to r231122a_1.png... done!
## Converting page 2 to r231122a_2.png... done!
## Converting page 3 to r231122a_3.png... done!
## Converting page 4 to r231122a_4.png... done!
## Converting page 5 to r231122a_5.png... done!
## Converting page 6 to r231122a_6.png... done!
You can see that the text is now readable:
new_text_ocr
## # A tibble: 6 × 3
## text page file
## <chr> <int> <chr>
## 1 "Exposing and acting on risks in a fast-changing\nworld\nEIOPA An… 1 r231…
## 2 "that might be emerging, we might also be able to open up new hor… 2 r231…
## 3 "industry. Recent earnings releases by large insurers show that h… 3 r231…
## 4 "Financial System (\n\nNGFS (Central Banks and Supervisors Networ… 4 r231…
## 5 "\nNGFS (Central Banks and Supervisors Network for Greening the F… 5 r231…
## 6 "\nLadies and gentlemen,\n\nTo come back to the animal-based meta… 6 r231…
Now you just have to integrate the now recognized text with the rest of the data. A last small step is to remove all the PNGs you have created by using tesseract.
# We remove all the .png we have created
png_to_remove <- list.files()[str_which(list.files(), "_\\d+\\.png")]
file.remove(png_to_remove)
And that’s it for the tutorial. You now have a data frame with the metadata of the speeches, and a data frame with the text, page by page for each speech.
If you want to scrap BIS speeches on a regular basis without scraping again what you have already collected, you may have a look at this script here, which is part of a project to collect central banks’ documents. You will also find in it some function to clean BIS data.
References
Harrison, John. 2022. RSelenium: R Bindings for ’Selenium WebDriver’. https://CRAN.R-project.org/package=RSelenium.
Perepolkin, Dmytro. 2023. Polite: Be Nice on the Web. https://CRAN.R-project.org/package=polite.
Wickham, Hadley. 2022. Rvest: Easily Harvest (Scrape) Web Pages. https://CRAN.R-project.org/package=rvest.
Wickham, Hadley, Mine Çetinkaya-Rundel, and Garrett Grolemund. 2023. R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. 2nd edition. Sebastopol, CA: O’Reilly Media.
I am not a specialist of html structures, but I was unable to extract the data using rvest only. I thus used RSelenium, and RSelenium only, even if most of the time you combine both packages. ↩︎
Aurélien Goutsmedt
Post-Doctoral Researcher
My research interests include history of economics, economic expertise and bibliometrics.