Scraping Working Papers from the European Central Bank Website
Scraping Tutorials 2
Table of Contents
After a first post on scraping the Bank of International Settlements database of speeches, this post teaches how to scrape documents from the European Central Bank website. More accurately, we won’t scrape the speeches of the ECB’s board members, as they are already available in a .csv format here. Rather, we will tackle research documents via the various series of working papers published by the ECB.
In the previous post, we learnt the difference between static and dynamic webpages. Dynamic webpages involve interaction with your web browser: in this case, you need the RSelenium (Harrison 2022) package.1
Here again, we will be confronted to dynamic webpages. However, these webpages raise novel issues. With the BIS database, the main issue was to go to the next page to scrape the metadata of the following speeches. We did it by finding how the page number was integrated into the URL. With the ECB website, the problem will be trickier for two reasons:
- First, all the documents are on the same page but as the page may be very long (depending on the type of documents), the page is not loaded entirely by your browser. You will thus learn to scroll down until all the documents are loaded.
- Second, some information (like the abstract or the JEL codes of a working paper) are hidden, and you have to click on a button to display them.
Before exploring that in details, let’s load the needed packages. This time, we will use rvest (Wickham 2022) in complement of RSelenium and polite (Perepolkin 2023). At the end of this post, we will test a second method with rvest only and not RSelenium to scrape working papers (but don’t spoil yourself!).
# pacman is a useful package to install missing packages and load them
if(! "pacman" %in% installed.packages()){
install.packages("pacman", dependencies = TRUE)
}
pacman::p_load(tidyverse,
RSelenium,
rvest,
polite,
glue)
A look at the ECB Website
Let’s say we want to scrape the metadata of ECB’s “occasional papers” at “https://www.ecb.europa.eu/pub/research/occasional-papers/html/index.en.html”.
Figure 1: ECB’s occasional papers
We can see that there is 333 occasional papers on the ECB website. Let’s try to scrape them. First, we use polite to “bow” in front of the ECB website. We specify who we are in the user_agent parameter, in order for the webmaster to contact us in case of problem. Indeed, we are trying here to follow some scraping ethical guidelines (find more developments on this issue here). The bow() function allows us to look at permissions for scraping.
ecb_op_path <- "https://www.ecb.europa.eu/pub/research/occasional-papers/html/index.en.html"
session <- bow(ecb_op_path,
user_agent = "polite R package - used for https://github.com/agoutsmedt/central_bank_database (aurelien.goutsmedt[at]uclouvain.be)")
session
## <polite session> https://www.ecb.europa.eu/pub/research/occasional-papers/html/index.en.html
## User-agent: polite R package - used for https://github.com/agoutsmedt/central_bank_database (aurelien.goutsmedt[at]uclouvain.be)
## robots.txt: 32 rules are defined for 1 bots
## Crawl delay: 5 sec
## The path is scrapable for this user-agent
By looking at the robots.txt file, we can see more in details which paths of the website are scrapable or not. Nothing about the publications path here!
cat(session$robotstxt$text)
## User-agent: *
## Sitemap: https://www.ecb.europa.eu/sitemap.xml
## Disallow: /*_content.bg.html$
## Disallow: /*_content.cs.html$
## Disallow: /*_content.da.html$
## Disallow: /*_content.de.html$
## Disallow: /*_content.el.html$
## Disallow: /*_content.en.html$
## Disallow: /*_content.es.html$
## Disallow: /*_content.et.html$
## Disallow: /*_content.fi.html$
## Disallow: /*_content.fr.html$
## Disallow: /*_content.ga.html$
## Disallow: /*_content.hr.html$
## Disallow: /*_content.hu.html$
## Disallow: /*_content.it.html$
## Disallow: /*_content.lt.html$
## Disallow: /*_content.lv.html$
## Disallow: /*_content.mt.html$
## Disallow: /*_content.nl.html$
## Disallow: /*_content.pl.html$
## Disallow: /*_content.pt.html$
## Disallow: /*_content.ro.html$
## Disallow: /*_content.sk.html$
## Disallow: /*_content.sl.html$
## Disallow: /*_content.sv.html$
## Disallow: /ecb/10ann/shared/movies/
## Disallow: /ecb/educational/pricestab/shared/movie/
## Disallow: /ecb/educational/shared/movies/
## Disallow: /paym/coll/assets/html/dla/EA/
## Disallow: /press/tvservices/webcast/shared/video/
## Disallow: /paym/coll/assets/html/dla/EA/
## Disallow: /events/conferences/shared/movie/
## Disallow: /euro/changeover/shared/data/
## Crawl-delay: 5
Let’s launch our bot.
remDr <- rsDriver(browser = "firefox",
port = 4444L,
chromever = NULL)
browser <- remDr[["client"]]
browser$navigate(ecb_op_path)
Sys.time(session$delay) # letting the page load
browser$findElement("css", "a.cross.linkButton.linkButtonLarge.floatRight.highlight-extra-light")$clickElement() # Refusing cookies
Scrolling down and opening supplementary menus
We can try something quickly: we extract the list of the occasional papers number (the “No. XXX” information just above the title).
categories <- browser$findElements("css selector", ".category") %>%
map_chr(., ~.$getElementText()[[1]])
tail(categories)
## [1] "No. 315" "No. 314" "No. 313" "No. 312" "No. 311" "No. 310"
We got something weird here. The last paper we got in the list is No. 310. But if we scroll all the way down to the page, we can see that the last paper should be “No. 1”.
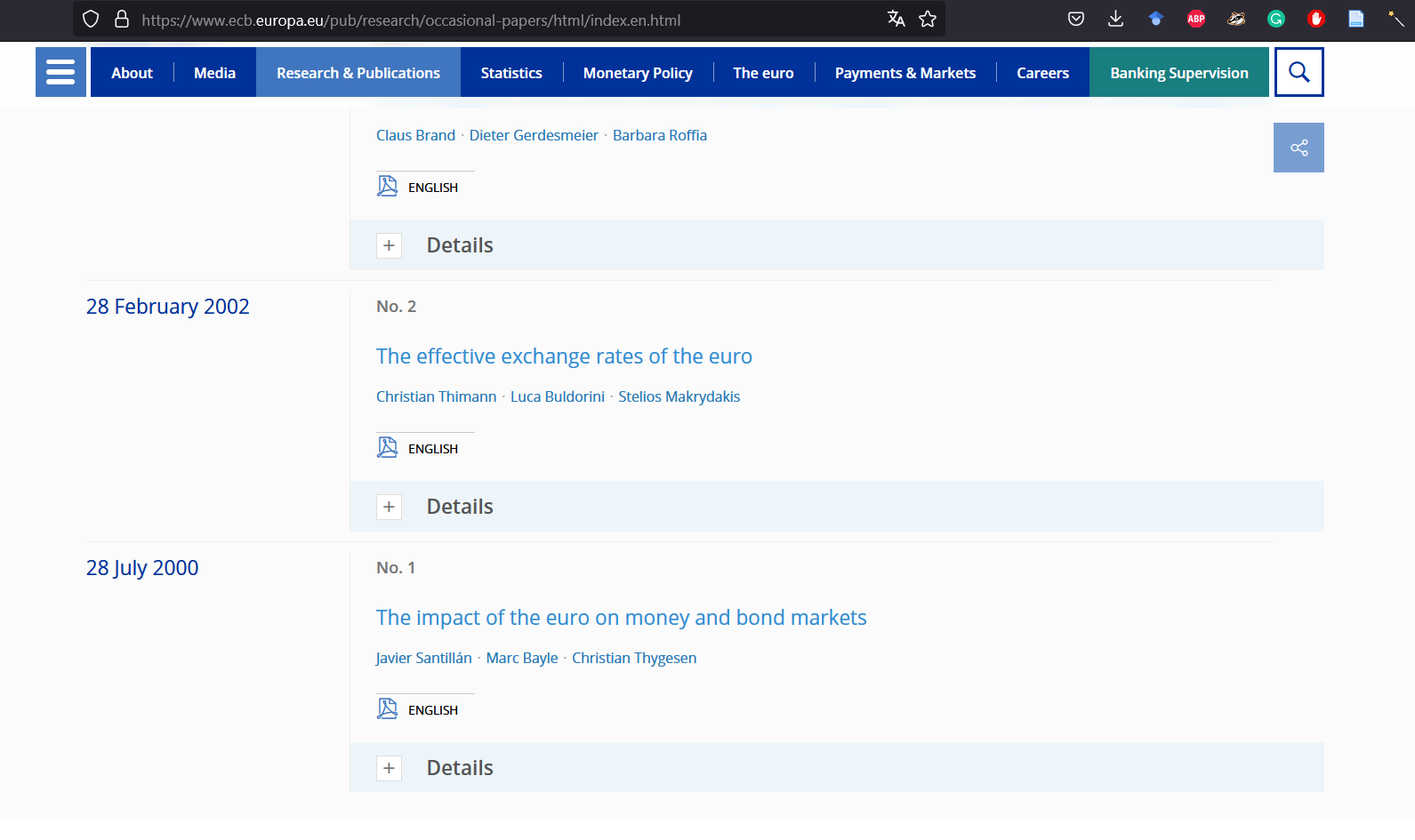
Figure 2: ECB’s occasional papers
Let’s dig a bit into the html code of the webpage. In Firefox, you can go to the supplementary tools and open the “web development tools”. You can see that there is something called lazyload-container.
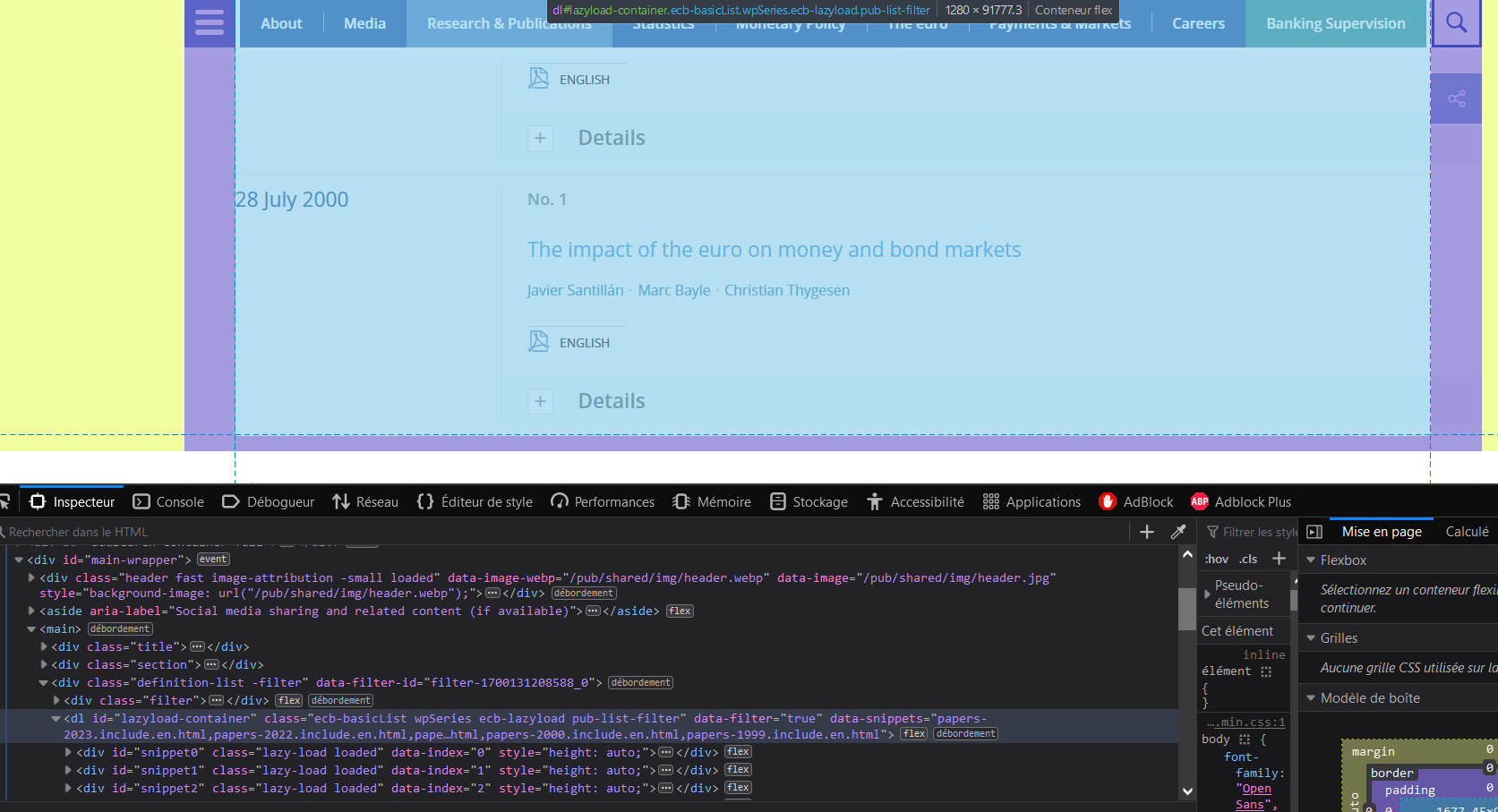
Figure 3: Digging into ECB’s website source code
As the number of occasional papers is quite big, for efficiency reasons, the website does not load the whole information. Consequently, if you want to scrape all the papers, you need to scroll down the page, and you need to scroll progressively to be sure that all the containers are loaded. The executeScript() function of RSelenium allows you to use some JavaScript code. Here, you don’t want to scroll horizontally, but you want to scroll vertically: you thus need to define the number of pixels by which you want to scroll down (let’s use 1600 to be sure that we will scroll down slowly). We will repeat this operation a certain number of time: as scrolling down by 1600 pixels is equivalent to scroll down by (a bit more than) five papers, we divide the number of papers by 5, to know the number of iterations of the scrolling down move.
scroll_height <- 1600
scroll_iteration <- str_extract(categories[1], "\\d+") %>%
as.numeric()/5
for(i in 1:ceiling(scroll_iteration)) {
browser$executeScript(glue("window.scrollBy(0,{scroll_height});"))
Sys.sleep(0.3)
}
Let’s check that now all the discussion papers are available:
categories <- browser$findElements("css selector", ".category") %>%
map_chr(., ~.$getElementText()[[1]])
length(categories)
## [1] 333
That’s all good. But we face a second issue: some important information are not visible yet. Indeed, by clicking on the “Details” button, you can access the abstract and the JEL codes of the paper.
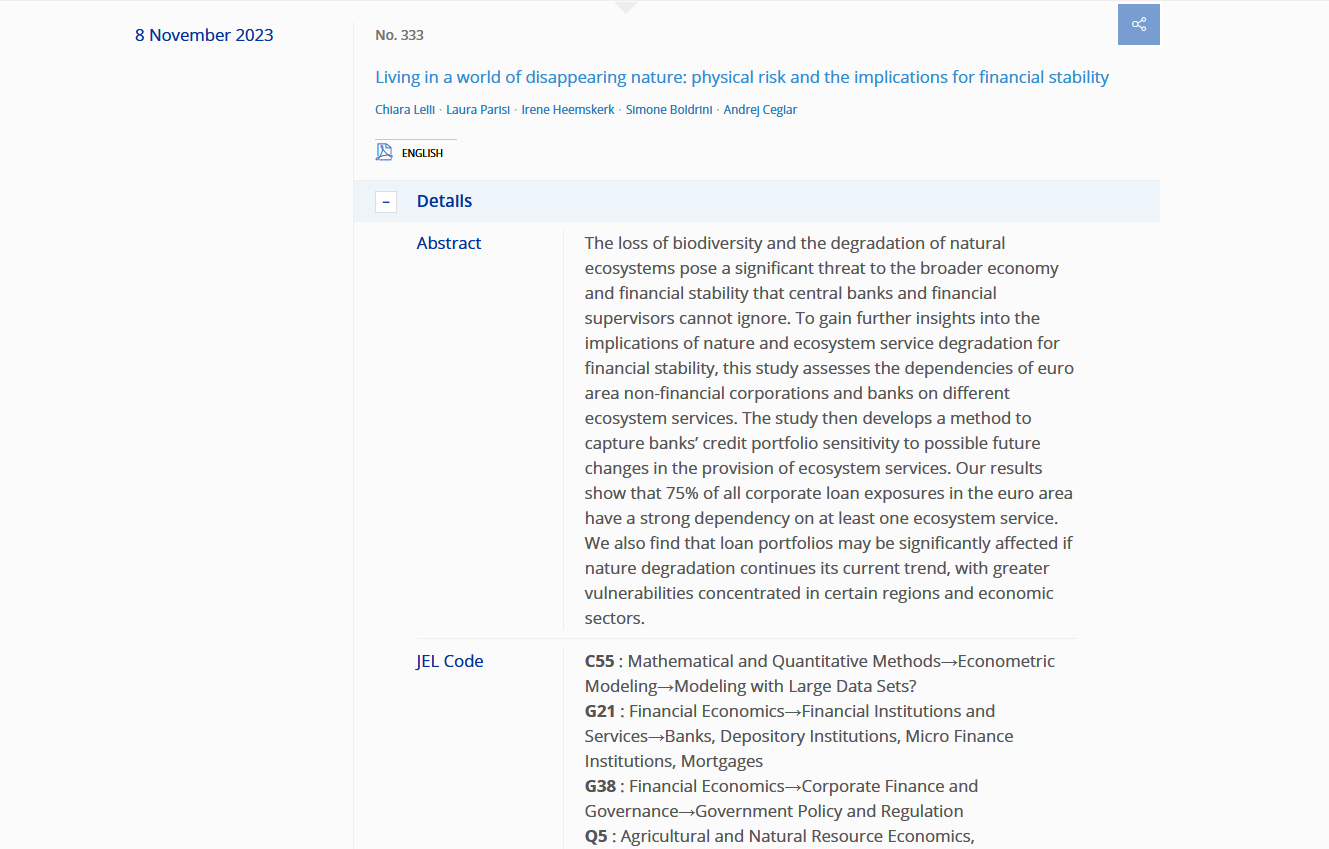
Figure 4: The ‘details’ menu
But as long as the Details menu is closed, the information is not accessible. So we need to find all the buttons that allow to click on the “Details” menu. But be careful, we want only the “Details” button, and not other types of button. As in the former post, the ScrapeMate Firefox add-on is essential to find the right CSS selector.
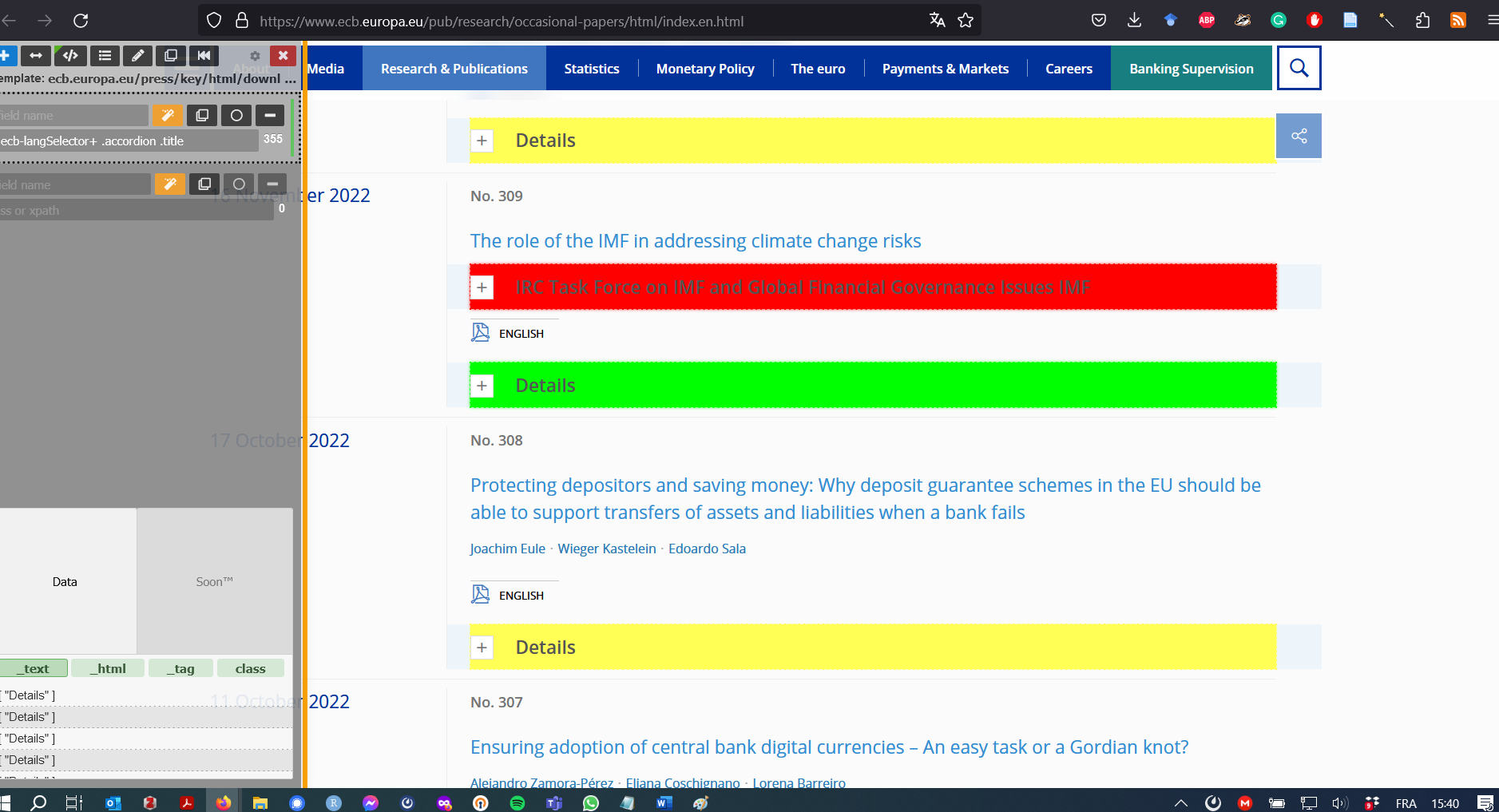
Figure 5: Using ScrapeMate Beta
We can now click on all the “Details” buttons, and only the “Details” buttons:
buttons <- browser$findElements("css selector", ".ecb-langSelector+ .accordion .header:nth-child(1) .title")
for(i in seq_along(buttons)){
buttons[[i]]$clickElement()
Sys.sleep(0.4)
}
Now, we have at our disposal all the information that is of interest to us. The remaining issue is that some information may be missing (or non-existent) for some papers (for instance, one paper has no author). So we extract the dates separately, and then we select the whole set of information for each paper (in the papers_whole_information object), and in this set, we extract in turn the title, the authors, the URL of the pdf, and the information in details.2
papers_whole_information <- browser$getPageSource()[[1]] %>% # we extract the whole info of each paper here (without the date)
read_html() %>%
html_elements("dd")
metadata <- tibble(
category = categories,
dates = browser$findElements("css selector", ".loaded > dt") %>%
map_chr(., ~.$getElementText()[[1]]),
titles = papers_whole_information %>%
html_elements(".category+ .title a") %>%
html_text(),
authors = papers_whole_information %>%
html_elements("ul") %>%
html_text2(),
details = papers_whole_information %>%
html_elements(".ecb-langSelector+ .accordion .content-box:nth-child(2)") %>%
html_text2(),
url_pdf = papers_whole_information %>%
html_elements(".authors+ .ecb-langSelector .pdf") %>%
html_attr("href")
)
head(metadata)
## # A tibble: 6 × 6
## category dates titles authors details url_pdf
## <chr> <chr> <chr> <chr> <chr> <chr>
## 1 No. 333 8 November 2023 Living in a world of disap… "Chiar… "Abstr… /pub/p…
## 2 No. 332 24 October 2023 The effects of high inflat… "Krzys… "Abstr… /pub/p…
## 3 No. 331 17 October 2023 The future of DAOs in fina… "Ellen… "Abstr… /pub/p…
## 4 No. 330 16 October 2023 Inflation, fiscal policy a… "Henri… "Abstr… /pub/p…
## 5 No. 329 20 September 2023 How usable are capital buf… "Georg… "Abstr… /pub/p…
## 6 No. 317 13 September 2023 Recent advances in the lit… "Rolan… "Abstr… /pub/p…
Two points of clarification here:
- the CSS selector must be selected carefully. For instance, a paper may have several “.title a”, because it gathers some complementary documents. Paper 209 is an example. So you only want the title after the category. Hence the selector “.category+ .title a”. That’s the same logic for the “details” menu: you don’t want what is in the Annex for instance. Also, you may have several pdf links, and you just want the pdf link below the authors, which is the pdf of the paper.
- the
authorsanddetailscolumns remain to be cleaned. Indeed, you can have several authors, and thedetailscolumn gathers information about the abstract and JEL_codes, but also, in rare occasion, the “taxonomy” and the “network”. That’s why we use thehtml_text2()function of rvest: each type of information is separated by a linebreak (“\n”).
Let’s clean the details. You first separate the lines and get something like that:
details_cleaned <- metadata %>%
select(category, details) %>%
separate_longer_delim(details, "\n") %>%
filter(! details == "")
head(details_cleaned, 20)
## # A tibble: 20 × 2
## category details
## <chr> <chr>
## 1 No. 333 Abstract
## 2 No. 333 The loss of biodiversity and the degradation of natural ecosystems …
## 3 No. 333 JEL Code
## 4 No. 333 C55 : Mathematical and Quantitative Methods→Econometric Modeling→Mo…
## 5 No. 333 G21 : Financial Economics→Financial Institutions and Services→Banks…
## 6 No. 333 G38 : Financial Economics→Corporate Finance and Governance→Governme…
## 7 No. 333 Q5 : Agricultural and Natural Resource Economics, Environmental and…
## 8 No. 332 Abstract
## 9 No. 332 The recent spike in inflation, unprecedented in the history of the …
## 10 No. 332 JEL Code
## 11 No. 332 C3 : Mathematical and Quantitative Methods→Multiple or Simultaneous…
## 12 No. 332 E3 : Macroeconomics and Monetary Economics→Prices, Business Fluctua…
## 13 No. 332 E6 : Macroeconomics and Monetary Economics→Macroeconomic Policy, Ma…
## 14 No. 331 Abstract
## 15 No. 331 Despite the crypto-market crash in the spring of 2022 and the colla…
## 16 No. 331 JEL Code
## 17 No. 331 F38 : International Economics→International Finance→International F…
## 18 No. 331 F39 : International Economics→International Finance→Other
## 19 No. 331 G23 : Financial Economics→Financial Institutions and Services→Non-b…
## 20 No. 331 G32 : Financial Economics→Corporate Finance and Governance→Financin…
What you need to do is to extract the category of information (“Abstract|JEL Code|Taxonomy|Network”), and the text below represents the content of this category of information. You can then pivot the data to fill each column for the paper. Of course, most columns for taxonomy and network will be empty. As you have several JEL codes for each paper, pivot_wider() creates list columns for each type of information. But you can “unnest” the columns with single values (“Abstract”, “Taxonomy”, and “Network”)
details_cleaned <- details_cleaned %>%
mutate(type = str_extract(details, "^Abstract$|^JEL Code$|^Taxonomy$|^Network$")) %>%
fill(type, .direction = "down") %>% # we replace NA values in the type column by the information above which is non NA
filter(! str_detect(details, "^Abstract$|^JEL Code$|^Taxonomy$|^Network$")) %>% # we remove the title rows
pivot_wider(names_from = type, values_from = details) %>%
unnest(cols = c("Abstract", "Taxonomy", "Network"))
head(details_cleaned)
## # A tibble: 6 × 5
## category Abstract `JEL Code` Network Taxonomy
## <chr> <chr> <list> <chr> <chr>
## 1 No. 333 The loss of biodiversity and the degrada… <chr [4]> <NA> <NA>
## 2 No. 332 The recent spike in inflation, unprecede… <chr [3]> <NA> <NA>
## 3 No. 331 Despite the crypto-market crash in the s… <chr [7]> <NA> <NA>
## 4 No. 330 This paper analyses the distributional i… <chr [6]> <NA> <NA>
## 5 No. 329 This paper analyses banks’ ability to … <chr [2]> <NA> <NA>
## 6 No. 317 Large swings in cross-border capital flo… <chr [2]> <NA> <NA>
Let’s “zoom” to the JEL code column:
head(details_cleaned %>% select(category, `JEL Code`) %>% unnest(`JEL Code`))
## # A tibble: 6 × 2
## category `JEL Code`
## <chr> <chr>
## 1 No. 333 C55 : Mathematical and Quantitative Methods→Econometric Modeling→Mod…
## 2 No. 333 G21 : Financial Economics→Financial Institutions and Services→Banks,…
## 3 No. 333 G38 : Financial Economics→Corporate Finance and Governance→Governmen…
## 4 No. 333 Q5 : Agricultural and Natural Resource Economics, Environmental and …
## 5 No. 332 C3 : Mathematical and Quantitative Methods→Multiple or Simultaneous …
## 6 No. 332 E3 : Macroeconomics and Monetary Economics→Prices, Business Fluctuat…
Finally, you just need to merge the details cleaned with the metadata:
metadata_cleaned <- metadata %>%
select(-details) %>%
left_join(details_cleaned)
head(metadata_cleaned)
## # A tibble: 6 × 9
## category dates titles authors url_pdf Abstract `JEL Code` Network Taxonomy
## <chr> <chr> <chr> <chr> <chr> <chr> <list> <chr> <chr>
## 1 No. 333 8 Novemb… Livin… "Chiar… /pub/p… The los… <chr [4]> <NA> <NA>
## 2 No. 332 24 Octob… The e… "Krzys… /pub/p… The rec… <chr [3]> <NA> <NA>
## 3 No. 331 17 Octob… The f… "Ellen… /pub/p… Despite… <chr [7]> <NA> <NA>
## 4 No. 330 16 Octob… Infla… "Henri… /pub/p… This pa… <chr [6]> <NA> <NA>
## 5 No. 329 20 Septe… How u… "Georg… /pub/p… This pa… <chr [2]> <NA> <NA>
## 6 No. 317 13 Septe… Recen… "Rolan… /pub/p… Large s… <chr [2]> <NA> <NA>
And you now have a nice table of metadata for ECB occasional papers! The post on the BIS explains then how to download the PDF, and how to run OCR if the text of the PDFs is not searchable. The code in this current post is also working for ECB’s “discussion papers” and “working papers”.
Another Method?
You can use the method above to scrape the metadata for the almost 3000 working papers of the ECB. But you can imagine that it takes a very long time to scroll down the page, and above all to open all the “Details” menu. RSelenium is wonderfully useful to interact with web browser, but sometimes, by digging into the source code of a webpage, you may find easier ways to extract relevant information.
And this is possible for the ECB research pages. We have already come across a clue to this earlier in this post. Indeed, let’s look again at the code related to the “lazyload-container”.
Figure 6: Digging into ECB’s website code
Actually it tells us that the website is loading some other pages, ending with “papers-2023.include.en.html”, “papers-2022.include.en.html”, etc., until “papers-1999.include.en.html”. Let’s try the first one: “https://www.ecb.europa.eu/pub/research/working-papers/html/papers-2023.include.en.html”
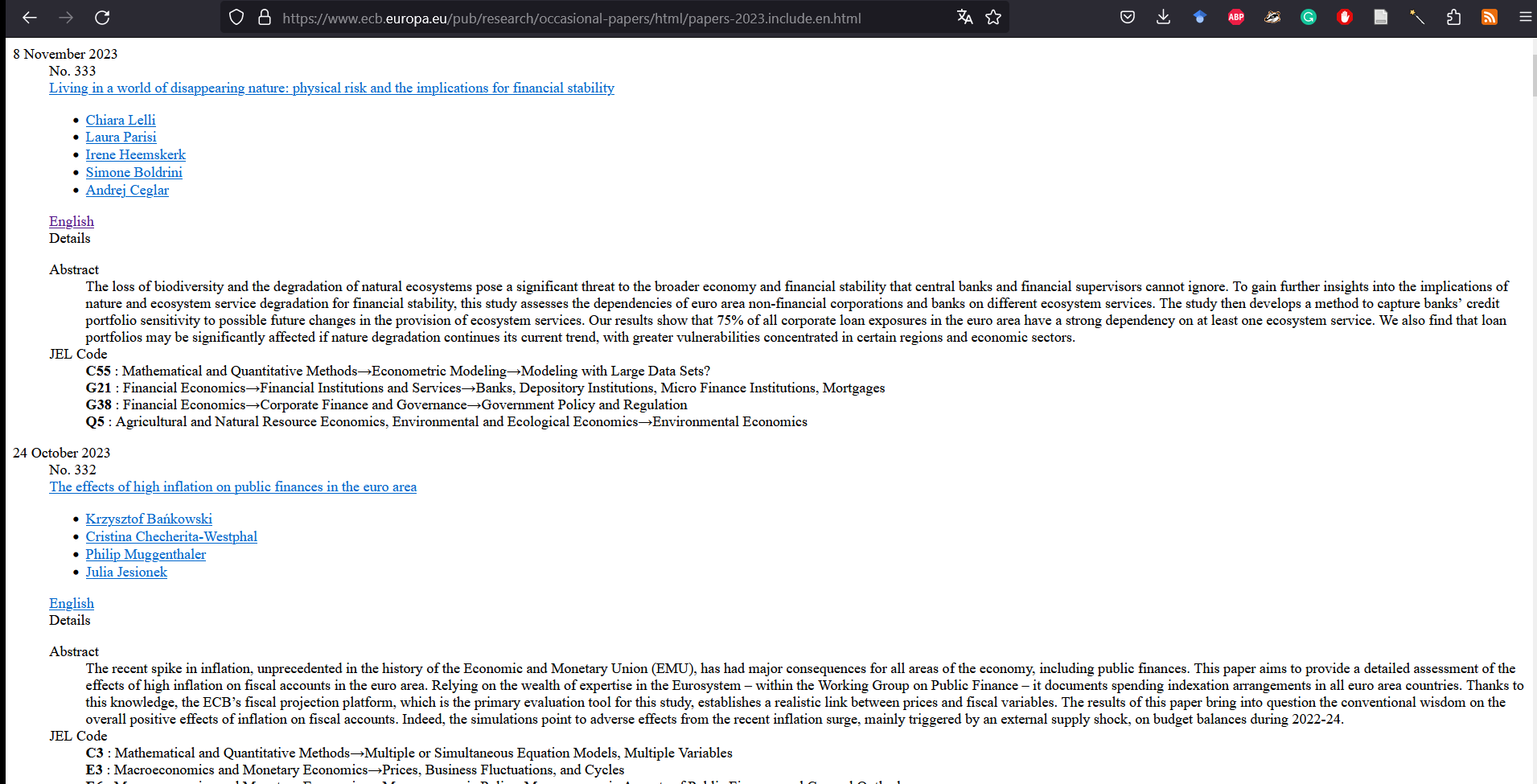
Figure 7: A simpler ECB page
So we can scrape quite easily the occasional papers for 2023:
url <- "https://www.ecb.europa.eu/pub/research/occasional-papers/html/papers-2023.include.en.html"
html_info <- read_html(url) %>%
html_elements(xpath = "/html/body/dd")
metadata <- tibble(
category = html_info %>%
html_elements(".category") %>%
html_text(),
dates = read_html(url) %>%
html_elements(".date") %>%
html_text(),
titles = html_info %>%
html_elements(".category+ .title a") %>%
html_text(),
authors = html_info %>%
html_elements("ul") %>%
html_text2(),
details = html_info %>%
html_elements(".ecb-langSelector+ .accordion .content-box:nth-child(2)") %>%
html_text2(),
url_pdf = html_info %>%
html_elements(".pdf") %>%
html_attr("href")
)
head(metadata)
References
Harrison, John. 2022. RSelenium: R Bindings for ’Selenium WebDriver’. https://CRAN.R-project.org/package=RSelenium.
Perepolkin, Dmytro. 2023. Polite: Be Nice on the Web. https://CRAN.R-project.org/package=polite.
Wickham, Hadley. 2022. Rvest: Easily Harvest (Scrape) Web Pages. https://CRAN.R-project.org/package=rvest.
Aurélien Goutsmedt
Post-Doctoral Researcher
My research interests include history of economics, economic expertise and bibliometrics.