Release of Ranystyle 0.0.999 (Development version)

Table of Contents
I am thrilled to announce the inaugural development release of Ranystyle! Ranystyle (pronounce “R-anystyle”) is designed to extract, parse and clean bibliographic references from an array of sources including PDFs, text documents, and references stored in a R objects. At its core, Ranystyle harnesses the power of the anystyle Ruby gem, wrapping (and extending) its capabilities within an intuitive R interface.
Initial Setup
You can install the development version of Ranystyle from GitHub with:
# install.packages("devtools")
devtools::install_github("agoutsmedt/Ranystyle")
Before diving into Ranystyle’s functionalities, ensure that Ruby and RubyGems are installed on your system. If you haven’t yet ventured into the Ruby world, no worries! Installation is straigthforward, and once set up, Ranystyle will seamlessly manage the rest.
To automatically install anystyle and anystyle-cli Ruby gems, simply run:
library(Ranystyle)
install_anystyle()
Utilizing Ranystyle in your Research Workflow
Ranystyle can be your go-to resource in various scenarios:
- Extracting references from multiple PDFs and converting them to
.bibformat. - Building a structured data frame from references cited across several PDFs.
- Parsing a vector of references stored in an R object to extract detailed information.
- Converting a bibliography in a PDF from one citation style to another in word.
Creating a .bib from a Collection of PDFs
The find_ref() function leverages the power of the ‘anystyle’ Ruby gem find function to identify reference sections and footnotes. It will extract the references cited in a PDF. Imagine having a set of PDFs and aiming to distill the references within (here we take the PDFs stored in the package):
library(Ranystyle)
# Locating the PDF documents bundled with the package
pdf_path <- system.file("extdata", package = "Ranystyle")
pdf_files <- list.files(pdf_path, pattern = "pdf$", full.names = TRUE)
pdf_files
## [1] "C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_1.pdf"
## [2] "C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_2.pdf"
## [3] "C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_3.pdf"
Let’s visualize the first page of references from one of these PDFs:
# Leveraging pdftools to extract a page as an image
library(pdftools)
page_image <- pdftools::pdf_convert(pdf = pdf_files[1],
format = 'png',
pages = 22)
## Converting page 22 to example_doc_1_22.png... done!
knitr::include_graphics(page_image)

Next, we extract the references, saving them in the versatile .bib format.
find_ref(input = pdf_files[1],
path = getwd(),
output_format = "bib",
overwrite = TRUE)
## [1] "anystyle --overwrite -f bib find C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_1.pdf C:/Users/goutsmedt/Documents/MEGAsync/Research/R/projets/website/content/en/post/2024-01-09-release-ranystyle-development"
To illustrate the extraction’s efficacy, let’s inspect the first lines of the generated .bib file:
# Locating and reading the .bib file corresponding to the first PDF
bib_file <- sub("pdf$", "bib", basename(pdf_files[1]))
# Read the first 10 lines of the .bib file
bib_lines <- readLines(bib_file, n = 26)
# Print the lines
cat(bib_lines, sep = "\n")
## @article{arnold2023a,
## author = {Arnold, M.},
## date = {2023},
## title = {ECB must do more to tackle inflation “Monster”, says christine lagarde’},
## journal = {Financial Times}
## }
## @article{barro1983a,
## author = {Barro, R.J. and Gordon, D.B.},
## date = {1983},
## title = {Rules, discretion and reputation in a model of monetary policy’},
## volume = {12},
## pages = {101–121},
## url = {https://doi.org/10.1016/0304-3932(83)90051-X.},
## doi = {10.1016/0304-3932(83)90051-X.},
## journal = {Journal of Monetary Economics},
## number = {1}
## }
## @article{b2009a,
## author = {Béland, D.},
## date = {2009},
## title = {Ideas, institutions, and policy change’},
## volume = {16},
## pages = {701–718},
## journal = {Journal of European Public Policy},
## number = {5}
## }
Transforming PDF References into a Data Frame
Ranystyle effortlessly bridges the gap between static PDF content and dynamic data analysis. Using the find_ref_to_df() function, you can convert references from PDFS directly into a data frame, specifically into a tibble, for enhanced usability and manipulation within the tidyverse ecosystem.
Let’s see how it works:
# Extracting references from PDFs into a data frame
extracted_refs <- find_ref_to_df(input = pdf_files)
## [1] "anystyle -f json find C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_1.pdf "
## [1] "anystyle -f json find C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_2.pdf "
## [1] "anystyle -f json find C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_3.pdf "
## [1] "anystyle --overwrite -f ref find C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_1.pdf ./"
## [1] "anystyle --overwrite -f ref find C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_2.pdf ./"
## [1] "anystyle --overwrite -f ref find C:/Users/goutsmedt/AppData/Local/R/win-library/4.3/Ranystyle/extdata/example_doc_3.pdf ./"
head(extracted_refs)
## # A tibble: 6 × 24
## id_doc doc id_ref author title year `container-title` volume pages
## <int> <chr> <chr> <list> <chr> <int> <chr> <chr> <chr>
## 1 1 example_doc… 1_1 <tibble> ECB … 2023 Financial Times <NA> <NA>
## 2 1 example_doc… 1_2 <tibble> Rule… 1983 Journal of Monet… 12 101–…
## 3 1 example_doc… 1_3 <tibble> Idea… 2009 Journal of Europ… 16 701–…
## 4 1 example_doc… 1_4 <tibble> A st… 1999 Scottish Journal… 46 17–39
## 5 1 example_doc… 1_5 <tibble> Tech… 2018 International Po… 12 328–…
## 6 1 example_doc… 1_6 <tibble> Late… 2003 Journal of Machi… 3 <NA>
## # ℹ 15 more variables: location <chr>, publisher <chr>, type <chr>, date <chr>,
## # other_date <chr>, other_title <chr>, url <chr>, issue <chr>, doi <chr>,
## # edition <chr>, genre <chr>, note <chr>, editor <chr>,
## # `collection-title` <chr>, full_ref <chr>
The find_ref_to_df() function not only parses the references but also integrates the option for further cleaning via clean_ref(). While automated cleaning is available, manual refinement is an option too. This dual approach ensures flexibility, allowing you to maintain control over the data quality. In any case, find_ref_to_df() creates a data frame with both extracted information, as well as the original full references.
# Preview the original full references for manual inspection and cleaning
head(extracted_refs$full_ref)
## [1] "Arnold, M. (2023). ECB must do more to tackle inflation “Monster”, says christine lagarde’. Financial Times"
## [2] "Barro, R. J., & Gordon, D. B. (1983). Rules, discretion and reputation in a model of monetary policy’. Journal of Monetary Economics, 12(1), 101–121. https://doi.org/10.1016/0304-3932(83)90051-X"
## [3] "Béland, D. (2009). Ideas, institutions, and policy change’. Journal of European Public Policy, 16(5), 701–718"
## [4] "Berger, H., & Haan, J. (1999). A state within the state? An event study on the bundesbank (1948–1973)’. Scottish Journal of Political Economy, 46(1), 17–39"
## [5] "Best, J. (2018). Technocratic exceptionalism: Monetary policy and the fear of democracy’. International Political Sociology, 12(4), 328–345"
## [6] "Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent Dirichlet Allocation’. Journal of Machine Learning Research, 3"
Dealing with String-Based References
Occasionally, you might already have references stored as strings in R, like this:
# Sample references in string format
references <- c("Thiemann, Matthias, Carolina Raquel Melches, and Edin Ibrocevic. 2021. “Measuring and Mitigating Systemic Risks: How the Forging of New Alliances Between Central Bank and Academic Economists Legitimize the Transnational Macroprudential Agenda.\" Review of international political economy 28 (6): 1433-1458",
"Dietsch, Peter, François Claveau, and Clément Fontan. 2018. Do Central Banks Serve the People? New York: John Wiley & Sons",
"Singleton, John. 2010. Central Banking in the Twentieth Century. Cambridge: Cambridge University Press",
"Mudge, Stephanie L., and Antoine Vauchez. 2018. “Too Embedded to Fail.” Historical Social Research/Historische Sozialforschung 43(3): 248-273",
"Lucas, Robert E. 1972. “Expectations and the Neutrality of Money”. Journal of Economic Theory 4(2): 103-124")
references
## [1] "Thiemann, Matthias, Carolina Raquel Melches, and Edin Ibrocevic. 2021. “Measuring and Mitigating Systemic Risks: How the Forging of New Alliances Between Central Bank and Academic Economists Legitimize the Transnational Macroprudential Agenda.\" Review of international political economy 28 (6): 1433-1458"
## [2] "Dietsch, Peter, François Claveau, and Clément Fontan. 2018. Do Central Banks Serve the People? New York: John Wiley & Sons"
## [3] "Singleton, John. 2010. Central Banking in the Twentieth Century. Cambridge: Cambridge University Press"
## [4] "Mudge, Stephanie L., and Antoine Vauchez. 2018. “Too Embedded to Fail.” Historical Social Research/Historische Sozialforschung 43(3): 248-273"
## [5] "Lucas, Robert E. 1972. “Expectations and the Neutrality of Money”. Journal of Economic Theory 4(2): 103-124"
In such case, the anystyle Ruby gem parse function, embodied in Ranystyle’s parse_ref() and parse_ref_to_df(), becomes your go-to solution. While parse_ref() allows you to create a .bib (or other file format like json), parse_ref_to_df() transforms these references into a structured data frame:
# Parsing string references into a data frame
extracted_refs <- parse_ref_to_df(input = references)
## [1] "anystyle --no-overwrite -f json parse ref_to_parse.txt "
head(extracted_refs)
## # A tibble: 5 × 14
## id_doc doc id_ref author title year `container-title` volume pages
## <int> <chr> <chr> <list> <chr> <int> <chr> <chr> <chr>
## 1 1 ref_to_pars… 1_1 <tibble> Meas… 2021 Review of intern… 28 1433…
## 2 1 ref_to_pars… 1_2 <tibble> Do C… 2018 <NA> <NA> <NA>
## 3 1 ref_to_pars… 1_3 <tibble> Cent… 2010 <NA> <NA> <NA>
## 4 1 ref_to_pars… 1_4 <tibble> Too … 2018 Historical Socia… 43 248–…
## 5 1 ref_to_pars… 1_5 <tibble> Expe… 1972 Journal of Econo… 4 103–…
## # ℹ 5 more variables: location <chr>, publisher <chr>, type <chr>, date <chr>,
## # issue <chr>
Effortlessly Transforming Bibliographic Styles in Word
Ranystyle’s versatility extends beyond data manipulation and .bib file creation. Suppose you need to directly transfer references into a Word document, perhaps to modify the referencing style. In that case, find_ref_to_word_bibliography comes to your rescue.1 This function is ideal for changing bibliographic style with ease:
# Transforming PDF references into a Word document with a specific style
find_ref_to_word_bibliography(input = file.path(pdf_path, pdf_files[1]),
csl_path = "path/to/your_style.csl")
Here’s an example of what the generated bibliography might look like:
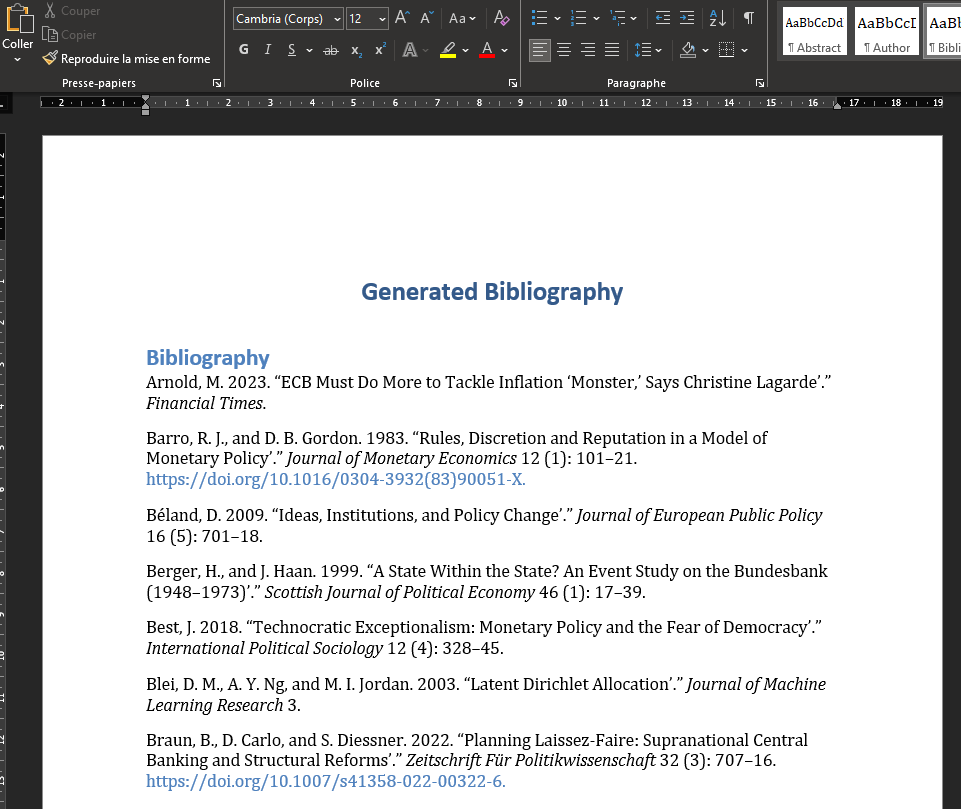
Explore the Possibilities with Ranystyle
The examples above are just a glimpse into the potential of Ranystyle. I encourage you to delve deeper into each function and explore the package main vignette for a comprehensive understanding of what Ranystyle can do.
As Ranystyle is still in its developmental infancy, your feedback is invaluable. Please share your experiences, report any issues, suggest improvements, or propose new features. Your input will be instrumental in refining and enhancing Ranystyle’s capabilities.
Credits
The anystyle parser, a core component of Ranystyle, has been developed by a talented team: Alex Fenton, Sylvester Keil, Johannes Krtek and Ilja Srna. anystyle is under copyright: Copyright 2011-2018 Sylvester Keil. All rights reserved. See the Licence for details.
The Ranystyle logo was created using DALL·E.
If you want to create a word bibliography from references stored into R, use parse_ref_to_word_bibliography(). ↩︎
Aurélien Goutsmedt
Post-Doctoral Researcher
My research interests include history of economics, economic expertise and bibliometrics.