Moissonner des documents du site de la Banque d'Angleterre
Scraping Tutorials 3
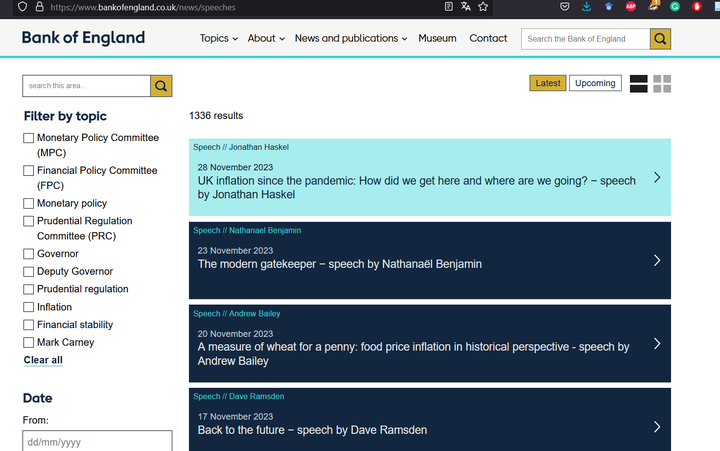
Table des matières
Dans le premier tutoriel sur le web scraping, j’ai expliqué comment récupérer la base de données des discours de banquiers centraux de la Banque des règlements internationaux. Le deuxième tutoriel s’est concentré sur les documents de travail du site web de la Banque centrale européenne. Dans ce troisième billet, je montrerai une méthode pour récupérer des documents sur le site de la Banque d’Angleterre.
Dans les deux premiers billets, nous avions une liste de documents sur une page web avec différentes informations (ou “métadonnées”) que nous voulions récupérer. Pour la BRI, nous avons dû comprendre la structure de l’URL, l’utiliser pour changer de page et récupérer les métadonnées de tous les discours qui nous intéressaient. Pour la BCE, nous devions plutôt faire défiler la page vers le bas et cliquer sur des menus pour ouvrir des détails supplémentaires. Ici, nous allons utiliser une approche radicalement différente, consistant à extraire la structure du site web, le “sitemap”, pour voir où nous pouvons trouver les métadonnées des documents.1
Contrairement aux deux premiers posts, nous n’aurons pas besoin de RSelenium (Harrison 2022) ici. Nous n’utiliserons que rvest (Wickham 2022) et polite (Perepolkin 2023). En effet, la méthode choisie n’implique pas d’interaction avec un navigateur web.
# pacman is a useful package to install missing packages and load them
if(! "pacman" %in% installed.packages()){
install.packages("pacman", dependencies = TRUE)
}
pacman::p_load(tidyverse,
rvest,
polite)
Explorer le site de la BoE
Jetons un coup d’oeil, par exemple, aux discours de la BoE sur https://www.bankofengland.co.uk/news/speeches.

Figure 1: Les discours de la BoE
Nous avons une liste de discours relativement similaire à celle que nous avions pour la BRI, avec une liste de pages que vous pouvez changer au bas de la page web. Cependant, l’URL reste la même lorsque vous passez à une autre page. Je n’ai pas trouvé de moyen de manipuler l’URL pour passer d’une page à l’autre. Mais vous pouvez facilement utiliser RSelenium pour cliquer sur le bouton afin de passer à la page suivante.
Néanmoins, nous pouvons collecter plus d’informations en cliquant sur chaque discours, car chaque discours a une page web dédiée comme celle-ci :

Figure 2: La page web d’un discours
Cela signifie que pour chaque discours des responsables politiques de la BoE, il existe une URL, et que nous devrions donc être en mesure de trouver cette URL à partir du “sitemap”.2
Explorer la structure du site
Comme expliqué dans le premier tutoriel, il est important de déclarer qui nous sommes au site web et de vérifier les règles de scraping sur ce site web en lisant le robot.txt.
root_url_BoE <- "https://www.bankofengland.co.uk"
user_agent <- "polite R package - used for https://github.com/agoutsmedt/central_bank_database (aurelien.goutsmedt[at]uclouvain.be)"
session <- bow(root_url_BoE,
user_agent = user_agent)
session$robotstxt$text
## [robots.txt]
## --------------------------------------
##
## User-agent: *
## Disallow: /boeapps/database/ShowChart.asp
## Disallow: /boeapps/database/_iadb-FromShowColumns.asp
## Disallow: /boeapps/iadb
## Disallow: /boeapps/titan
## Disallow: /error
## Disallow: /forms
## Disallow: /mfsd
## Disallow: /search
## Disallow: /test-folder
## Disallow: /-/media/boe/files/markets/benchmarks/sonia-statement-of-compliance-with-the-iosco-principles-for-financial-benchmarks.pdf
##
## Sitemap: https://www.bankofengland.co.uk/_api/sitemap/getsitemap
## Host: www.bankofengland.co.uk
Le robot.txt nous indique également l’URL du sitemap :
sitemap <- session$robotstxt$sitemap$value
sitemap
## [1] "https://www.bankofengland.co.uk/_api/sitemap/getsitemap"
Cette page web rassemble une (très longue) liste de tous les URLs existants du site web. Vous pouvez essayer d’y jeter un coup d’oeil dans votre navigateur, mais le temps de chargement est très long. Le plus simple est de la lire directement ici via rvest.
xml_sitemap <- rvest::read_html(sitemap)
xml_sitemap %>% html_element(xpath = "body")
## {html_node}
## <body>
## [1] <urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"><url><loc>htt ...
On voit que c’est l’argument “loc” qui nous intéresse.
data_frame_sitemap <- tibble(hyperlink= xml_sitemap %>%
rvest::html_elements(xpath = ".//loc") %>%
rvest::html_text()) %>%
filter(hyperlink != root_url_BoE) # we exclude the base url that we don't need anymore
data_frame_sitemap
## # A tibble: 13,140 × 1
## hyperlink
## <chr>
## 1 https://www.bankofengland.co.uk/about
## 2 https://www.bankofengland.co.uk/about/corporate-responsibility
## 3 https://www.bankofengland.co.uk/about/corporate-responsibility/carbon-target…
## 4 https://www.bankofengland.co.uk/about/corporate-responsibility/charities-of-…
## 5 https://www.bankofengland.co.uk/about/get-involved
## 6 https://www.bankofengland.co.uk/about/get-involved/citizens-panels
## 7 https://www.bankofengland.co.uk/about/get-involved/citizens-panels/cara-pete…
## 8 https://www.bankofengland.co.uk/about/get-involved/citizens-panels/emma-young
## 9 https://www.bankofengland.co.uk/about/get-involved/citizens-panels/insights-…
## 10 https://www.bankofengland.co.uk/about/get-involved/citizens-panels/nick-chen…
## # ℹ 13,130 more rows
Nous avons une liste de 13140 URLs. Ce qu’il nous faut maintenant, c’est comprendre le contenu de ces URLs : nous pouvons le savoir en regardant ce qui suit l’URL de base :
data_frame_sitemap <- data_frame_sitemap %>%
mutate(category = str_remove(hyperlink, "https://www.bankofengland.co.uk/") %>%
str_remove("/.*"))
unique(data_frame_sitemap$category)
## [1] "about" "accessibility"
## [3] "agents-summary" "alternative-liquidity-facility"
## [5] "annual-report" "archive"
## [7] "article" "asset-purchase-facility"
## [9] "bank-liabilities-survey" "bank-overground"
## [11] "banking-services" "banknotes"
## [13] "careers" "ccbs"
## [15] "climate-change" "contact"
## [17] "coronavirus" "cost-of-living"
## [19] "credit-conditions-review" "credit-conditions-survey"
## [21] "decision-maker-panel" "education"
## [23] "eu-withdrawal" "events"
## [25] "explainers" "external-mpc-discussion-paper"
## [27] "faq" "financial-policy-summary-and-record"
## [29] "financial-stability" "financial-stability-in-focus"
## [31] "financial-stability-paper" "financial-stability-report"
## [33] "freedom-of-information" "gold"
## [35] "independent-evaluation-office" "inflation-attitudes-survey"
## [37] "inflation-report" "legal"
## [39] "letter" "markets"
## [41] "minutes" "monetary-policy"
## [43] "monetary-policy-report" "monetary-policy-summary-and-minutes"
## [45] "museum" "news"
## [47] "paper" "payment-and-settlement"
## [49] "prudential-regulation" "quarterly-bulletin"
## [51] "record" "report"
## [53] "research" "rss"
## [55] "sitemap" "speech"
## [57] "statement" "statistics"
## [59] "sterling-monetary-framework" "sterling-money-market-survey"
## [61] "stress-testing" "subscribe-to-emails"
## [63] "systemic-risk-survey" "the-digital-pound"
## [65] "vulnerability-disclosure-policy" "weekly-report"
## [67] "whistleblowing" "working-paper"
Nous pouvons maintenant filtrer les URL en fonction de ce que nous voulons récupérer. Pour cette fois, oublions les discours et disons que nous sommes intéressés par les “minutes” :
minutes_urls <- data_frame_sitemap %>%
filter(category == "minutes")
minutes_urls
## # A tibble: 669 × 2
## hyperlink category
## <chr> <chr>
## 1 https://www.bankofengland.co.uk/minutes/1997/monetary-policy-commit… minutes
## 2 https://www.bankofengland.co.uk/minutes/1997/monetary-policy-commit… minutes
## 3 https://www.bankofengland.co.uk/minutes/1997/monetary-policy-commit… minutes
## 4 https://www.bankofengland.co.uk/minutes/1997/monetary-policy-commit… minutes
## 5 https://www.bankofengland.co.uk/minutes/1997/monetary-policy-commit… minutes
## 6 https://www.bankofengland.co.uk/minutes/1997/monetary-policy-commit… minutes
## 7 https://www.bankofengland.co.uk/minutes/1997/monetary-policy-commit… minutes
## 8 https://www.bankofengland.co.uk/minutes/1998/monetary-policy-commit… minutes
## 9 https://www.bankofengland.co.uk/minutes/1998/monetary-policy-commit… minutes
## 10 https://www.bankofengland.co.uk/minutes/1998/monetary-policy-commit… minutes
## # ℹ 659 more rows
Récupérer les métadonnées des Minutes
Grâce aux URL des minutes, nous avons les dates des minutes. Concentrons-nous sur les minutes de 2023.
minutes_urls <- minutes_urls %>%
mutate(dates = str_extract(hyperlink, "(?<=/)\\d{4}(?=/)") %>% as.integer()) %>%
filter(dates == 2023)
Nous pouvons jeter un coup d’œil au premier URL de nos données :

Figure 3: Un exemple de page de minutes
En utilisant rvest, nous extrayons d’abord le code .html de la première page web. Vous pouvez voir que le texte du procès-verbal peut être extrait directement de cette page web. Nous voulons extraire le titre du document, sa date, son résumé et le contenu du texte.
page <- minutes_urls %>%
slice(1) %>%
pull(hyperlink) %>%
read_html
extracted_title <- page %>%
html_nodes("h1") %>%
html_text()
extracted_date <- page %>%
html_nodes(".published-date") %>%
html_text(trim = TRUE) %>%
str_extract("\\d+ [A-z]+ \\d+$") %>%
dmy()
# As the abstract and the text may gather several paragraphs, the object could be a vector of several strings. We thus save these strings as a list format (because we want one line per URL/document)
abstract <- page %>%
html_nodes(".hero") %>%
html_text(trim= TRUE) %>%
list()
text <- page %>%
# We extract the titles and the text together
html_nodes('.page-section .content-block h2 , .page-section .content-block h3, .page-section .content-block .page-content p') %>%
html_text() %>%
list()
metadata <- tibble(title = extracted_title,
date = extracted_date,
abstract = abstract,
text = text)
metadata
## # A tibble: 1 × 4
## title date abstract text
## <chr> <date> <list> <lis>
## 1 Minutes of the Meeting of the Court of Directors he… 2023-06-08 <chr> <chr>
Nous pouvons jeter un coup d’œil aux premières lignes du texte extrait :
metadata %>%
pull(text) %>%
unlist() %>%
.[1:30] %>%
str_c(collapse = "\n") %>%
cat()
## Present:
## David Roberts, Chair
## Andrew Bailey, Governor
## Ben Broadbent, Policy
## Sir Jon Cunliffe, Deputy Governor – Financial Stability
## Sir Dave Ramsden, Deputy Governor – Markets & Banking
## Sam Woods, Deputy Governor – Prudential Regulation
## Sabine Chalmers
## Lord Jitesh Gadhia
## Anne Glover
## Sir Ron Kalifa
## Diana Noble
## Frances O’Grady
## Tom Shropshire
## In attendance:
## Ben Stimson, Chief Operating Officer
## Secretary:
## Sebastian Walsh
## 1. Conflicts, Minutes and Matters Arising
## There were no conflicts declared in relation to the present agenda.
## The minutes of the meeting held on 8 February 2023 were approved.
## The Chair noted that a number of steps had been introduced to support the effectiveness of Court meetings.
## The Chair welcomed Ruth Smith to the meeting and noted that Ruth had been appointed as interim Secretary of the Bank.
## 2. Governor’s Update
## The Governor updated Court on recent developments in the banking system.
## The Governor reflected that recent weeks had seen two banks with UK operations fail and parts of the financial sector come under stress. Silicon Valley Bank (SVB) and its UK subsidiary failed on 10 March due to a deposit run following significant losses in the US parent. Court observed the speed of the run on SVB. Court noted the factors underlying this, including the extent to which social media now drives bank runs.
## The PRA’s approach to the UK operations of SVB ensured a greater degree of financial resilience, particularly the subsidiarisation policy. Over the weekend that SVB UK failed, the Bank conducted a successful resolution transaction – demonstrating the effective operation of the UK’s resolution regime. SVB UK’s capital instruments were written down, and the firm was sold to HSBC. The Bank’s actions protected both depositors and public funds.
## The Governor set out that the resolution plan for Credit Suisse was well-rehearsed by the UK, US and Swiss authorities. However, the Swiss authorities had not used the resolution plan. Instead, the Swiss conducted a going-concern sale underpinned by some public support, which in turn effected a full write-down of subordinated debt instruments, while equity was only partially written down. There had been some brief fallout in AT1 markets following this action, but swift communications from the UK and EU authorities on their approach to the creditor hierarchy in resolution had stemmed this.
## Though SVB and Credit Suisse had failed for different reasons, the events had taken place in close proximity to each other. As a result of this, investors perceived that the outlook for the global banking sector was uncertain. The Governor noted that more broadly the backdrop for these events was an uncertain outlook for global economic activity. The Bank was monitoring the financial system closely, particularly the impact of recent events on financial markets, UK banks and economic conditions. The Governor noted that UK banks are well capitalised, liquid and resilient to continue supporting households and businesses.
## Providing further detail about this work, Sam Woods explained that the FPC and the PRA had been closely examining developments across the financial system as a whole.
Il ne nous reste plus qu’à construire une boucle pour récupérer les métadonnées de toutes les minutes. Pour éviter de surcharger le site web du BoE, nous devons fixer un délai entre la navigation sur les différentes URL.
delay <- session$delay
Nous utiliserons également la fonction TryCatch() pour éviter de rompre la boucle en cas d’erreur (par exemple lorsqu’une page n’est pas chargée correctement).
errors <- list()
metadata <- vector(mode = "list", length = nrow(minutes_urls))
for(i in minutes_urls$hyperlink){
tryCatch({
page <- read_html(i)
cat(paste("Now scraping URL: ", i, "\n"))
Sys.sleep(delay)
extracted_title <- page %>%
html_nodes("h1") %>%
html_text()
extracted_date <- page %>%
html_nodes(".published-date") %>%
html_text(trim = TRUE) %>%
str_extract("\\d+ [A-z]+ \\d+$") %>%
dmy()
abstract <- page %>%
html_nodes(".hero") %>%
html_text(trim= TRUE) %>%
list()
text <- page %>%
# We extract the titles and the text together
html_nodes('.page-section .content-block h2 , .page-section .content-block h3, .page-section .content-block .page-content p') %>%
html_text() %>%
list()
metadata[[i]] <- tibble(title = extracted_title,
url = i,
date = extracted_date,
abstract = abstract,
text = text)
}, error = function(e) {
cat(paste("Problem with scraping URL: ", i, "\n"))
errors[[i]] <- i
})
}
minutes_metadata <- bind_rows(metadata)
minutes_metadata
Lorsque tous les documents ont leur propre page web, les données sitemap deviennent une information puissante pour faciliter votre scraping. Ici, elle peut être utilisée pour récupérer facilement tous les documents publiés par la Banque d’Angleterre. Cependant, la structure de la page n’est pas exactement la même au sein d’une catégorie (le texte des minutes n’est pas disponible sur les pages web avant 2022 mais vous pouvez récupérer l’URL du PDF), et entre les catégories (regardez par exemple un discours ou un document de travail). Par conséquent, un code plus raffiné est nécessaire. Vous trouverez un tel script ici.
Bibliographie
Harrison, John. 2022. RSelenium: R Bindings for ’Selenium WebDriver’. https://CRAN.R-project.org/package=RSelenium.
Perepolkin, Dmytro. 2023. polite: Be Nice on the Web. https://CRAN.R-project.org/package=polite.
Wickham, Hadley. 2022. rvest: Easily Harvest (Scrape) Web Pages. https://CRAN.R-project.org/package=rvest.
Cette méthode est inspirée d’un script initialement écrit par François Claveau et Jérémie Dion pour un projet de recherche sur la Banque d’Angleterre. ↩︎
En fait, la même méthode pourrait être utilisée pour récupérer les discours de la base de données de la Banque des règlements internationaux. ↩︎
Aurélien Goutsmedt
Chercheur Postdoctoral et Chargé de Cours
Je travaille sur l’histoire de l’économie et l’expertise économique.