Petit guide pour apprendre R à destination des historiens de l'économie

Table des matières
Pourquoi apprendre R ?
Les débats sur l’utilisation de méthodes quantitatives dans l’étude de l’histoire de l’économie ont fleuri ces dernières années - voir par exemple le numéro spécial dans le Journal of Economic Methodology (Edwards, Giraud, and Schinckus 2018)- et de nombreuses contributions récentes ont utilisé la bibliométrie, l’analyse de réseau ou la modélisation des sujets. 1. Lorsque l’envie vous prend de vous essayer aux méthodes quantitatives (comme cela a été le cas pour moi il y a quelques années), la première question que vous vous posez est sans doute “mais comment faire, et quels outils dois-je apprendre à utiliser ?”.
Il existe de nombreux logiciels (certains gratuits, d’autres payants) qui vous permettront d’utiliser la bibliométrie, l’analyse de réseaux ou la modélisation de sujets. En fonction de ce que vous voulez faire, vous devrez apprendre chaque logiciel correspondant–après vous être assuré que l’outil est approprié pour accomplir la tâche que vous avez à l’esprit. C’est ce que j’ai fait lorsque j’ai voulu utiliser l’analyse de réseau pour l’un de mes articles : J’ai appris à utiliser le très bon GEPHI. Cependant, Gephi est très utile pour manipuler des réseaux, mais à condition que vous ayez déjà construit votre réseau. Et si vous souhaitez utiliser d’autres types d’analyse quantitative sur vos données (par exemple l’analyse de texte et la modélisation thématique), vous devrez trouver un autre logiciel. C’est pourquoi, après ce premier projet de recherche intégrant des méthodes quantitatives, j’ai pris une autre direction : J’ai appris à programmer en R.2.
Il est évident que l’apprentissage de R a un coût d’entrée plus élevé que l’apprentissage de GEPHI - 2 ou 3 heures devraient suffire pour apprendre les bases de ce dernier. Mais il offre de nombreux avantages et, à moyen et long terme, de grandes économies d’échelle :
Il vous permettra de manipuler vos données plus facilement et plus rapidement qu’en utilisant Excel (que ce soit de manière programmatique ou manuelle). Vous pourrez faire des choses que vous ne pouvez pas faire avec Excel. Et cela devient de plus en plus vrai au fur et à mesure que votre ensemble de données s’accroît.
Vous pourrez utiliser différentes méthodes quantitatives (bibliométrie, analyse de réseau, traitement du langage naturel, économétrie, apprentissage automatique, etc.) et construire des visualisations en apprenant un seul et unique langage (grâce aux nombreux paquets implémentés dans R).
L’écriture de “scripts” en R vous permet de réexécuter les mêmes tâches sans effort supplémentaire à chaque fois que vos données changent ou que vous souhaitez modifier un paramètre de votre analyse. En outre, ces scripts constituent une ressource que vous pourrez réutiliser dans d’autres projets.
En dehors des méthodes quantitatives à proprement parler, l’apprentissage de R vous permettra de faire plusieurs autres choses :
- rédiger efficacement livres, articles, rapports et diapositives grâce à Rmarkdown (Allaire et al. 2021) ;
- publier en ligne vos analyses et construire des tableaux de bord et des applications3.
Si vous êtes convaincu que la programmation en R pourrait vous être utile en tant qu’historien de l’économie, vous avez maintenant besoin de ressources pour apprendre à coder. Voici une liste de packages et de tutoriels utiles que j’aurais aimé avoir lorsque j’ai commencé à apprendre à programmer en R et que j’ai beaucoup utilisés depuis pour améliorer mes compétences.
Première étape : les bases
La toute première étape consiste évidemment à télécharger et à installer R et Rstudio sur votre ordinateur, ainsi qu’à comprendre les bases du langage R et la manière d’utiliser Rstudio. Le premier chapitre de McConville (2021) ou cette leçon de R-ladies Sydney sont de bons points de départ.
Une fois que vous êtes un peu familiarisé avec ce qu’est R et le fonctionnement de Rstudio, je pense que la priorité est de vous familiariser avec la collection de paquets tydiverse (Wickham 2021a ; Wickham et al. 2019). Un guide très fiable est évidemment l’ouvrage de Wickham et Gromelund (2017) R for Data Science. Dans ce livre, vous apprendrez à importer des données, à les transformer, à les visualiser et à leur appliquer des modèles statistiques4.
Un autre détour utile lorsque vous avez progressivement appris les bases de R, est de comprendre comment organiser votre flux de travail avec R et Rstudio (comment organiser vos fichiers ? pourquoi et comment créer un “projet RStudio” ?) : vous pouvez trouver des informations utiles dans le deuxième chapitre de Jenny Bryan (2017). Je ne veux pas charger la barque trop tôt, mais lorsque vous aurez commencé votre premier projet, il pourrait être utile d’apprendre les bases du contrôle de version et de git. C’est quelque chose qui sera indispensable lorsque vous travaillerez collectivement sur un projet dans Rstudio. Parce que l’utilisation de git n’est pas très intuitive et que vous vous arracherez probablement les cheveux au début, il vaut mieux s’habituer à utiliser git dès le début, même (et surtout ?) lorsque vous travaillez seul. Vous serez confronté à des cas simples et vous aurez alors moins peur d’utiliser le versioning git dans des projets collectifs. Jennyfer Bryan (2019) propose une documentation riche pour apprendre à utiliser git et github–ce dernier étant fondamental pour partager son code et donner des explications sur les projets sur lesquels on travaille.5
R offre de formidables outils pour construire une grande variété de visualisations. Le package ggplot2 (Wickham et al. 2021 ; Wickham 2016) est évidemment le premier de ces outils, et vous pouvez trouver une documentation dense ici. Le livre de Kieran Healy (2018) est également une bonne lecture pour apprendre ggplot2 tout en réfléchissant aux meilleures pratiques pour construire des visualisations de données. Un des avantages de ggplot2 est qu’il est accompagné de nombreuses extensions (nouveaux types de visualisations, outils pour personnaliser de différentes manières les visualisations produites avec ggplot2, nouveaux thèmes et palettes de couleurs, animation, etc) listées ici. Je reconnais que l’apprentissage de cette “grammaire graphique” est loin d’être facile au début, car vous devrez connaître de nombreuses fonctions et prendre en compte de nombreuses caractéristiques lors de la production de visualisations quantitatives. L’extension esquisse (Meyer and Perrier 2021) pourrait vous permettre de réduire le coût d’entrée et de vous familiariser progressivement avec les fonctions de ggplot2 : il s’agit d’un complément de Rstudio qui vous permet de construire interactivement vos visualisations.
Si vous souhaitez produire des visualisations dynamiques et interactives, le paquet plotly (Sievert et al. 2021 ; Sievert 2020) offre de nombreuses possibilités. L’avantage de plotly est que, pour certaines fonctionnalités de base, vous pouvez convertir les visualisations produites avec ggplot2 en visualisations interactives avec une seule ligne de code. Mais plotly pour R permet également des personnalisations plus complexes qui nécessitent d’étudier plus en profondeur les différentes fonctions du package (voir une documentation détaillée ici).
Voilà pour les bases : il est évident que vous ne maîtriserez pas tous les packages ci-dessus en un jour, et vous les découvrirez progressivement en travaillant sur votre propre projet de recherche. Cependant, vous aurez probablement besoin de la plupart d’entre eux dans tous les projets quantitatifs que vous entreprendrez, que vous souhaitiez effectuer une simple analyse statistique sur une base de données prosopographique d’économistes formés au MIT, une comparaison des mots utilisés par Adam Smith et David Ricardo, ou une analyse bibliométrique des publications sur la discrimination dans les revues académiques économiques. Les outils suivants que je vais vous présenter visent des usages plus spécifiques.
Apprendre la bibliométrie et l’analyse de réseau
La bibliométrie est utile aux historiens de l’économie pour comprendre comment la discipline a évolué, quelles sont les influences majeures pour des sous-domaines spécifiques, comment différentes communautés ont structuré la discipline à différentes périodes, etc6. L’analyse de réseaux vient en complément de la bibliométrie pour produire des réseaux de couplage bibliographique, de co-citation, de mots-clés ou de co-auteurs.
Un premier package, bibliometrix, offre différentes fonctions allant de l’extraction de données bibliométriques à partir de différentes plateformes (comme Web of Science ou Scopus), au calcul de statistiques et à la construction de réseaux. Je ne l’ai jamais utilisé de manière intensive, pour deux raisons :
- Je travaillais sur de grands ensembles de données et bibliometrix semblait un peu lent pour cela ;
- J’ai trouvé les fonctions un peu comme des boîtes noires, et pas vraiment compatibles avec l’esprit tidyverse. Cependant, il semble très riche et je suis sûr qu’il vaut la peine d’être exploré.
Une fois que vous avez vos données - ce qui est loin d’être une étape facile7—J’ai développé, avec l’aide d’Alexandre Truc et de François Claveau, un package pour rendre la création de très grands réseaux de données bibliographiques facile et rapide : biblionetwork (Goutsmedt, Truc, and Claveau 2023). Ce dont vous avez besoin en entrée est un corpus et les références citées par ce corpus, et vous serez en mesure de créer facilement une liste de liens entre articles, références, auteurs, institutions, etc., avec différentes mesures de poids pour ces liens.
Une fois que vous avez vos arêtes/liens, vous pouvez créer un réseau à l’aide du package igraph (Csardi and Nepusz 2006). igraph est un package très riche qui comporte de nombreuses fonctions permettant de calculer des statistiques sur les réseaux (comme les mesures de centralité), de trouver des grappes et d’organiser les nœuds dans l’espace. Cependant, la manipulation des réseaux avec igraph n’est pas toujours très intuitive. Heureusement, le package tidygraph (Pedersen 2020) vous permet de transformer les réseaux en données “ordonnées”, dans l’esprit tidyverse, et de manipuler les réseaux en conséquence. De même, le paquet ggraph (Pedersen 2021), qui est une extension de ggplot2, permet de produire de belles visualisations de réseaux.

Figure 1: Un exemple de réseau tiré du projet Mapping Macroeconomics
Alexandre Truc et moi-même développons actuellement un autre package, networkflow, pour faciliter la manipulation des réseaux, grâce à tidygraph et ggraph. L’objectif est de construire des routines pour baliser et accélérer l’analyse des réseaux, depuis leur création jusqu’à leur visualisation, en passant par le clustering et la spatialisation. Dans un futur proche, le package intégrera des outils pour l’analyse dynamique des réseaux (en comparant l’évolution de différents réseaux dans le temps).
Essayez l’exploration de texte et la modélisation de sujets
Le text mining est une approche essentielle pour analyser de grands corpus et peut donc apporter des informations utiles aux historiens de l’économie.
La première étape consiste à transformer le texte de vos documents en données lisibles dans R. Cela implique tout d’abord que le texte de vos documents soit reconnaissable. Pour vérifier cela, vous pouvez simplement copier le texte d’une page aléatoire de votre corpus et le coller dans un éditeur de texte. Si le texte n’est pas reconnaissable, ou si la qualité n’est pas bonne, vous devriez lancer Optical Character Recognition. Dans mes anciens projets, j’ai utilisé un OCR très efficace via un logiciel acheté, PDF Element. Je l’ai trouvé meilleur que le moteur OCR tesseract. Cependant, je n’ai pas poussé les possibilités du moteur jusqu’au bout. tesseract a été implémenté dans R dans un package (Ooms 2021b). Si vous avez un pdf et que la reconnaissance de texte est bonne, vous pouvez utiliser le package pdftools (Ooms 2021a) pour extraire le texte et le manipuler avec R.
Une fois que le texte de votre corpus est prêt à être importé dans R, vous pouvez commencer l’analyse. Julia Silge et David Robinson (2020) ont écrit un excellent livre d’introduction au text mining dans R. Il s’appuie sur le package tidytext (Robinson and Silge 2021; Silge and Robinson 2016), qui apporte des fonctions simples pour faire des choses compliquées (tokeniser des textes, calculer des statistiques comme TF-IDF, etc.). Si vous voulez en savoir plus sur la tokenisation, le stemming et la lemmatisation, les stop words, ou les embeddings de mots, vous pouvez passer à l’étape suivante et lire la première partie de Supervised Machine Learning for Text Analysis in R (Silge and Hvitfeldt 2021).
Une fois que vous avez acquis une certaine maîtrise de l’extraction de texte, de son nettoyage et de son prétraitement, et du calcul de statistiques standard, vous pouvez vous intéresser à des techniques plus complexes et à l’apprentissage automatique. Dans ce cas, la modélisation thématique peut offrir des résultats très riches. Il s’agit de l’utilisation d’un modèle (le Latent Dirichlet Allocation étant le plus utilisé) pour identifier k sujets (k étant déterminé par le modélisateur) dans votre corpus. Le résultat de votre modélisation thématique est que chaque document de votre corpus est représenté comme un mélange de thèmes, et chaque thème comme un mélange de mots. Pour exécuter la modélisation thématique dans R, vous trouverez des informations intéressantes dans le chapitre correspondant de Silge et Robinson (2020). Dans ce chapitre, ils utilisent le package topicmodels (Grün and Hornik 2021, 2011).8. Mais je trouve que le package stm (Roberts, Stewart, and Tingley 2020) est aussi très utile avec de très belles fonctions implémentées. Il vous permet de croiser votre modélisation thématique avec les métadonnées de votre corpus.
Enfin, pour vous aider à faire fonctionner la modélisation des sujets dans R (mais aussi pour d’autres problématiques de text mining), vous pouvez consulter les conseils et bonnes pratiques discutés par Welbers, Van Atteveldt, and Benoit (2017) ou Banks et al. (2018). Plus généralement, R offre de nombreuses ressources pour le text mining et le Natural Language Processing (NLP) : vous pouvez trouver un aperçu des différents packages existants ici.
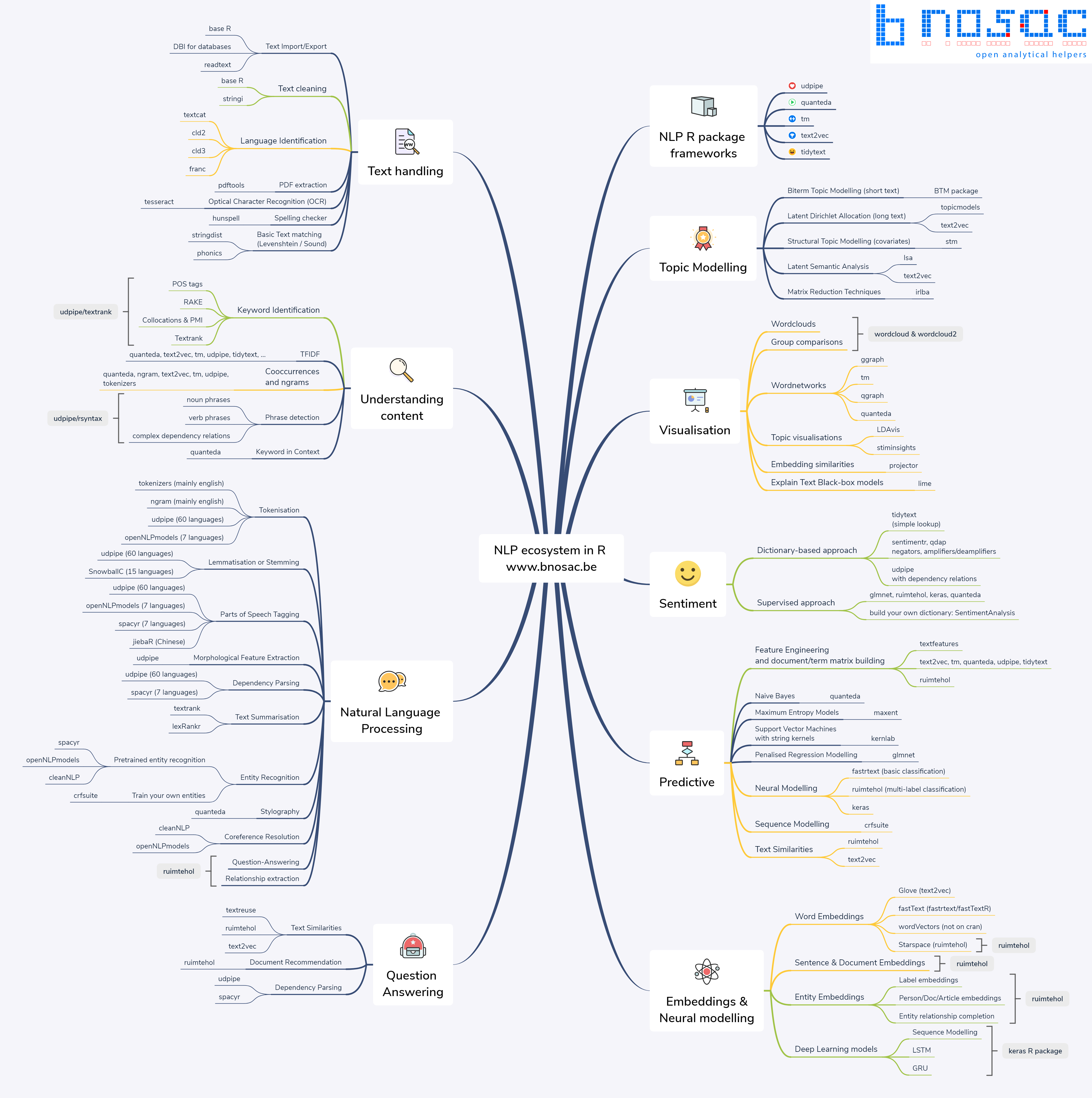
Figure 2: L’écosystème du Natural Language Processing avec R
Se plonger dans la modélisation et l’apprentissage automatique
Je ne suis pas du tout un spécialiste de la modélisation et de l’apprentissage automatique, mais j’espère avoir l’occasion de me former dans les années à venir. En effet, il y a de nombreuses occasions où cela peut être utile pour les historiens. Si vous voulez vous rafraîchir la mémoire en économétrie en apprenant R, vous pouvez regarder le livre de Schmelzer (2021) que vous pouvez lire en ligne. En ce qui concerne l’apprentissage automatique, qui peut avoir de nombreuses applications en histoire de l’économie, notamment avec les techniques de classification, j’ai trouvé que Greenwell (2020) offre une bonne introduction à l’implémentation en R de différents algorithmes d’apprentissage automatique - vous pouvez le lire ici.
Pour aider les utilisateurs de R dans leur travail de modélisation, la collection de packages tidymodels peut être très utile, que ce soit pour le prétraitement de vos données, l’évaluation de votre modèle ou l’ajustement de vos paramètres. Le site web contient également de nombreux tutoriels intéressants pour apprendre l’approche tidymodels.
La programmation plus loin : Fonctions, fonctions, fonctions… et packages
Une fois que vous avez progressé dans la maîtrise de ces différentes méthodes et que vous avez amélioré vos compétences en matière de codage R, une tâche importante consiste à solidifier votre code et à le rendre fiable pour les travaux futurs. La première étape lorsque vous écrivez du code est de le documenter : donnez à votre script une structure claire, expliquez pourquoi vous utilisez cette fonction, gardez une trace des chemins qui ont échoué, indiquez ce que vous pourriez améliorer, etc. Cela peut être utile pour les collaborateurs ou les lecteurs de vos scripts, mais surtout pour vous, car un script désordonné est le meilleur moyen de perdre beaucoup de temps deux ou trois mois plus tard, lorsque vous devrez revenir sur votre projet (par exemple après avoir reçu les rapports des arbitres sur votre article). Vous pouvez trouver des conseils utiles ici sur la structuration de votre script et le nommage des objets. Comme l’explique Wickham and Grolemund (2017) ici, il est également très utile de revenir sur votre script et de le réécrire pour le rendre plus simple et plus clair.
Une étape importante de cette réécriture consiste à transformer une partie de votre code en fonctions. Une bonne règle générale est que si vous copiez et collez la même partie de votre code plus de deux fois, il pourrait être utile de la transformer en fonction. Vous trouverez des informations utiles sur la programmation correcte des fonctions dans Wickham (2019), à commencer par le chapitre sur les fonctions9.
Si vous avez un ensemble de fonctions que vous utilisez régulièrement dans un ou plusieurs de vos projets, vous devriez envisager d’écrire un package. Même si vous ne prévoyez pas initialement de partager votre code, l’écriture d’un package est une bonne discipline pour écrire du bon code et pour la reproductibilité. Plus tard, il sera utile de faire circuler votre code et, peut-être, si vous êtes satisfait du résultat et pensez qu’il pourrait être utile à d’autres codeurs R, vous voudrez le publier sur le CRAN. Pour l’écriture d’un package, Wickham and Bryan (2021) propose un guide essentiel que vous pouvez également trouver en ligne ici. Si vous souhaitez partager votre package, pkgdown vous aide à créer facilement un site web documentant votre package.
Rédiger et diffuser votre travail avec R Mardown
Enfin, vous aurez probablement besoin de diffuser et de publier vos résultats. Heureusement, R Markdown est l’outil idéal pour cela. Outre la possibilité d’exécuter du code dans votre document R Markdown et donc d’afficher les résultats, il offre de nombreux avantages comme la gestion bibliographique et l’intégration de Zotero10. Il permet de créer des documents html, pdf et word. Pour pdf, il s’appuie sur LaTeX et utilise Pandoc pour la conversion à partir du langage markdown.11. Avec R Markdown, vous pourrez rédiger des rapports (automatisés) et des tableaux de bord, des articles universitaires, des livres et des thèses (Xie 2021 ; Xie 2016), des diapositives, et même créer votre propre site Web (Xie, Dervieux, and Presmanes Hill 2021 ; Xie, Hill, and Thomas 2017) et des applications (Chang et al. 2021 ; Wickham 2021b).
Pour apprendre à utiliser R Markdown, vous pouvez vous référer à Xie, Allaire, and Grolemund (2018) et Riederer, Xie, and Dervieux (2021) avec les sites web correspondants ici et ici.
Bibliography
Allaire, JJ, Yihui Xie, Jonathan McPherson, Javier Luraschi, Kevin Ushey, Aron Atkins, Hadley Wickham, Joe Cheng, Winston Chang, and Richard Iannone. 2021. Rmarkdown: Dynamic Documents for r. https://CRAN.R-project.org/package=rmarkdown.
Banks, George C., Haley M. Woznyj, Ryan S. Wesslen, and Roxanne L. Ross. 2018. “A Review of Best Practice Recommendations for Text Analysis in R (and a User-Friendly App).” Journal of Business and Psychology 33 (4): 445–59. https://doi.org/10.1007/s10869-017-9528-3.
Bryan, Jenny. 2017. STAT 545: Data Wrangling, Exploration, and Analysis with R.
Bryan, Jennyfer. 2019. Happy Git and GitHub for the useR.
Chang, Winston, Joe Cheng, JJ Allaire, Carson Sievert, Barret Schloerke, Yihui Xie, Jeff Allen, Jonathan McPherson, Alan Dipert, and Barbara Borges. 2021. Shiny: Web Application Framework for r. https://shiny.rstudio.com/.
Claveau, François, and Yves Gingras. 2016. “Macrodynamics of Economics: A Bibliometric History.” History of Political Economy, January.
Csardi, Gabor, and Tamas Nepusz. 2006. “The Igraph Software Package for Complex Network Research.” InterJournal Complex Systems: 1695. https://igraph.org.
Dowle, Matt, and Arun Srinivasan. 2021. Data.table: Extension of ‘Data.frame‘. https://CRAN.R-project.org/package=data.table.
Edwards, José, Yann Giraud, and Christophe Schinckus. 2018. “A Quantitative Turn in the Historiography of Economics?” Journal of Economic Methodology 25 (4): 283–90. https://doi.org/10.1080/1350178X.2018.1529133.
Goutsmedt, Aurélien, Alexandre Truc, and François Claveau. 2023. “biblionetwork: An R Package for Creating Different Types of Bibliometric Networks.” Zenodo. https://doi.org/10.5281/zenodo.7677369.
Greenwell, Bradley Boehmke & Brandon. 2020. Hands-On Machine Learning with R.
Grün, Bettina, and Kurt Hornik. 2011. “topicmodels: An R Package for Fitting Topic Models.” Journal of Statistical Software 40 (13): 1–30. https://doi.org/10.18637/jss.v040.i13.
———. 2021. Topicmodels: Topic Models. https://CRAN.R-project.org/package=topicmodels.
Healy, Kieran. 2018. Data Visualization: A Practical Introduction. Princeton, NJ: Princeton University Press.
Herfeld, Catherine, and Malte Doehne. 2019. “The Diffusion of Scientific Innovations: A Role Typology.” Studies in History and Philosophy of Science Part A 77 (October): 64–80. https://doi.org/10.1016/j.shpsa.2017.12.001.
McConville, Chester Ismay and Albert Y. Kim Foreword by Kelly S. 2021. Statistical Inference via Data Science.
Meyer, Fanny, and Victor Perrier. 2021. Esquisse: Explore and Visualize Your Data Interactively.
Ooms, Jeroen. 2021a. Pdftools: Text Extraction, Rendering and Converting of PDF Documents. https://CRAN.R-project.org/package=pdftools.
———. 2021b. Tesseract: Open Source OCR Engine.
Pedersen, Thomas Lin. 2020. Tidygraph: A Tidy API for Graph Manipulation. https://CRAN.R-project.org/package=tidygraph.
———. 2021. Ggraph: An Implementation of Grammar of Graphics for Graphs and Networks. https://CRAN.R-project.org/package=ggraph.
Riederer, Emily, Yihui Xie, and Christophe Dervieux. 2021. R Markdown Cookbook.
Roberts, Margaret, Brandon Stewart, and Dustin Tingley. 2020. Stm: Estimation of the Structural Topic Model. http://www.structuraltopicmodel.com/.
Robinson, David, and Julia Silge. 2020. Text Mining with R.
———. 2021. Tidytext: Text Mining Using Dplyr, Ggplot2, and Other Tidy Tools. https://github.com/juliasilge/tidytext.
Schmelzer, Alexander Gerber, Martin Arnold. 2021. Introduction to Econometrics with R.
Sievert, Carson. 2020. Interactive Web-Based Data Visualization with r, Plotly, and Shiny. Chapman; Hall/CRC. https://plotly-r.com.
Sievert, Carson, Chris Parmer, Toby Hocking, Scott Chamberlain, Karthik Ram, Marianne Corvellec, and Pedro Despouy. 2021. Plotly: Create Interactive Web Graphics via Plotly.js. https://CRAN.R-project.org/package=plotly.
Silge, Julia, and Emil Hvitfeldt. 2021. Supervised Machine Learning for Text Analysis in R.
Silge, Julia, and David Robinson. 2016. “Tidytext: Text Mining and Analysis Using Tidy Data Principles in r.” JOSS 1 (3). https://doi.org/10.21105/joss.00037.
Welbers, Kasper, Wouter Van Atteveldt, and Kenneth Benoit. 2017. “Text Analysis in R.” Communication Methods and Measures 11 (4): 245–65. https://doi.org/10.1080/19312458.2017.1387238.
Wickham, Hadley. 2016. Ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York. https://ggplot2.tidyverse.org.
———. 2019. Advanced R, Second Edition. 2nd edition. Boca Raton: Chapman and Hall/CRC.
———. 2021a. Tidyverse: Easily Install and Load the Tidyverse. https://CRAN.R-project.org/package=tidyverse.
———. 2021b. Welcome | Mastering Shiny.
Wickham, Hadley, Mara Averick, Jennifer Bryan, Winston Chang, Lucy D’Agostino McGowan, Romain François, Garrett Grolemund, et al. 2019. “Welcome to the tidyverse.” Journal of Open Source Software 4 (43): 1686. https://doi.org/10.21105/joss.01686.
Wickham, Hadley, and Jennifer Bryan. 2021. Welcome! | R Packages.
Wickham, Hadley, Winston Chang, Lionel Henry, Thomas Lin Pedersen, Kohske Takahashi, Claus Wilke, Kara Woo, Hiroaki Yutani, and Dewey Dunnington. 2021. Ggplot2: Create Elegant Data Visualisations Using the Grammar of Graphics. https://CRAN.R-project.org/package=ggplot2.
Wickham, Hadley, and Garrett Grolemund. 2017. R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. 1st edition. Sebastopol, CA: O’Reilly Media.
Xie, Yihui. 2016. Bookdown: Authoring Books and Technical Documents with R Markdown. Boca Raton, Florida: Chapman; Hall/CRC. https://bookdown.org/yihui/bookdown.
———. 2021. Bookdown: Authoring Books and Technical Documents with r Markdown. https://CRAN.R-project.org/package=bookdown.
Xie, Yihui, J. J. Allaire, and Garrett Grolemund. 2018. R Markdown: The Definitive Guide. Boca Raton, Florida: Chapman; Hall/CRC. https://bookdown.org/yihui/rmarkdown.
Xie, Yihui, Christophe Dervieux, and Alison Presmanes Hill. 2021. Blogdown: Create Blogs and Websites with r Markdown. https://CRAN.R-project.org/package=blogdown.
Xie, Yihui, Alison Presmanes Hill, and Amber Thomas. 2017. Blogdown: Creating Websites with R Markdown. Boca Raton, Florida: Chapman; Hall/CRC. https://bookdown.org/yihui/blogdown/.
Pour les lecteurs francophones, vous trouverez une introduction aux données et méthodes quantitatives appliquées à l’histoire de l’économie, ainsi que plusieurs exemples d’utilisation de ces méthodes ici ↩︎
Je ne discuterai pas ici de la question de savoir si R ou Python convient mieux aux enquêtes quantitatives. Mon choix de R est totalement dépendant du chemin parcouru : Je travaillais à l’époque sur un projet collectif dont certains membres programmaient en R. Il était plus facile pour moi de suivre leur chemin et de leur demander de l’aide ↩︎
Ce site est notamment réalisé grâce au package R blogdown (Xie, Dervieux, and Presmanes Hill 2021) ↩︎
Un autre outil majeur lorsque vous traitez de très grands ensembles de données est le package data.table (Dowle and Srinivasan 2021), qui augmente considérablement la vitesse de programmation. Vous pouvez trouver de nombreux tutoriels sur les fonctionnalités de data.table sur le site web du package ↩︎
Voir par exemple la page github d’un projet sur lequel je travaille avec Alexandre Truc. ↩︎
Pour des exemples d’utilisation de la bibliométrie en histoire de l’économie, voir Claveau and Gingras (2016) ou Herfeld and Doehne (2019) ↩︎
La collecte de données bibliométriques n’est pas une tâche facile, car elle dépend de votre accès aux différentes bases de données et aux types d’informations que vous recherchez. De plus, il y a souvent beaucoup de nettoyage à faire sur les données que vous avez pu télécharger. J’essaierai de faire un billet de blog clarifiant ces questions bientôt. ↩︎
Voir le blog de Julia Silge pour d’autres exemples de modélisation de sujets en R–et pour de nombreux autres exemples de modélisation et de prédiction avec R ↩︎
Si vous programmez avec dplyr, cette vignette peut également vous être utile. Idem pour data.table ici. ↩︎
Vous pouvez lire ceci pour voir comment Rstudio facilite l’interaction entre R Mardown et Zotero ↩︎
Voir ce billet de blog pour connaître les avantages de l’écriture en markdown et de l’utilisation de pandoc plutôt que d’un éditeur de texte comme Word ↩︎
Aurélien Goutsmedt
Chercheur Postdoctoral et Chargé de Cours
Je travaille sur l’histoire de l’économie et l’expertise économique.