Introduction aux méthodes quantitatives appliquées à l'histoire de la pensée économique et à l'épistémologie économique
Introduction : Méthodes quantitatives et HPE/Philosophie économique
Objectif général de cette introduction aux méthodes quantitatives:
- Introduire à la diversité de ces méthodes, aux débats en histoire de la pensée et épistémologie économique sur l’usage de ces méthodes, ainsi qu’aux récents travaux produits avec ces méthodes.
- Rentrer dans le détail de deux types de recherches quantitatives: la bibliométrie utilisant l’analyse de réseau ; l’analyse de texte et la léxicométrie.
- Comprendre un peu mieux ces méthodes par la pratique. Dans le meilleur des cas, les cas pratiques permettront aux étudiants de reproduire certaine partie de l’analyse sur leur propre sujet de recherche.
Cette première partie vise à donner quelques points de repères sur l’état de l’usage des méthodes quantitatives dans le champ de l’histoire de la pensée économique et la philosophie/épistémologie de l’économie. Elle s’attache ensuite à clarifier les différentes sources de données et les types de méthodes quantitatives. Le but est de donner une vision d’ensemble, tout en introduisant du vocabulaire utile, des ressources et des exemples d’usages de ces données et méthodes.
Dans un deuxième temps du cours, différents cas pratiques sont proposés:
- la bibliométrie et à l’usage de l’analyse de réseau appliquée à la bibliométrie (proposées par Aurélien Goutsmedt, en 2021 et 2022);
- la textométrie et l’analyse de texte assistée par ordinateur (proposées par Justine Loulergue, en 2021);
- l’application des statistiques multidimensionnelles à l’histoire de la pensée économique (proposée par Julien Gradoz, en 2022).
Les débats sur l’usage des méthodes quantitatives
Si les méthodes quantitatives ont de longue date étaient utilisées et discutées dans la discipline (par exemple, Backhouse 1998), quoique de manière dispersée et occasionnelle, il ne fait pas de doute que les années récentes ont vu croître de manière conséquente le nombre de publications utilisant ces méthodes, mais encore plus les publications débattant de leur utilité ou de la nécessité d’aller plus loin dans cette direction.
Un bon exemple de ces débats est le numéro spécial du Journal of Economic Methodology de 2018, intitulé “Not Everything that can be Counted Counts: Historiographic Reflections on Quantifying Economics” Cherrier et Svorenčík (2018).
Avec Cherrier et Svorenčík (2018), on défendra ici une approche “mixte”, qui souligne la complémentarité des méthodes qualitatives et quantitatives, et qui prend bien soin d’analyser à quelles questions de recherche ces méthodes peuvent répondre.
De manière générale, l’opposition et la méfiance, d’intensités variables, que l’on trouve chez certains historiens de la pensée et philosophe de l’économie, envers les travaux quantitatifs reposent en partie sur des arguments qui ne tiennent pas pour rejeter ces méthodes:
- méfiance qui vient d’abord d’un manque de connaissance des méthodes, notamment du fait qu’elles sont encore peu utilisées dans le champ. Mais pourquoi les rejeter de prime abord, plutôt que de les juger sur leurs résultats, et sur les histoires qu’elles permettent de développer, les recherches qu’elles encouragent?
- Une grande partie de l’opposition/méfiance envers ces méthodes s’appuie sur des arguments qui mettent en garde contre l’application automatique et non-réflexive de ces méthodes. Même si l’argument de la “boîte noir” est à prendre aux sérieux dans toute approche quantitative, l’argument précédent est relativement symétrique, et s’applique également aux méthodes “qualitatives”. Souvent en histoire de la pensée économique, les présupposés historiographiques et méthodologiques de certains travaux de recherche ne sont rarement questionnés et mis en avant. Qu’il ou elle utilise des méthodes qualitatives ou quantitatives (ou les deux, bien entendu), le chercheur ou la chercheuse doit s’efforcer de considérer les points faibles et les angles morts de son approche, ainsi que les questions auxquelles ces méthodes permettent et ne permettent pas de répondre.
Il est certain que le développement récent de la puissance de calcul des ordinateurs, l’accessibilité des données et la multiplication des ressources pédagogiques pour apprendre à utiliser des outils quantitatifs ou à programmer, ont permis de pouvoir utiliser bien plus facilement certaines méthodes quantitatives, sans pour autant en maîtriser totalement les tenants et les aboutissant. Cela peut créer le risque d’inciter à l’intégration d’outils quantitatifs relevant plus de l’excitation pour un outil nouveau que d’un réel intérêt en termes d’apport et de support à la littérature existante. Il n’empêche que cela ne peut que difficilement justifier de se passer de ce genre de méthodes, et devrait plutôt inciter à favoriser l’émergence de “bonnes pratiques” et la montée en compétence des chercheurs dans le champ.
Les méthodes quantitatives me semblent importantes en histoire de la pensée et en philosophie économique pour plusieurs raisons:
- diminution du biais de confirmation. Tout chercheur à une tendance à chercher des confirmations dans les sources qu’il étudie, plutôt qu’à chercher des contradictions, remettant en cause ses travaux passés ou bien ce qu’il cherche à prouver dans son travail en cours. On peut lutter le plus possible contre ce biais, mais il risque toujours de jouer un rôle à un moment ou un autre. Même si elles ne sont pas épargnées par ce biais, loin s’en faut, les méthodes quantitatives permettent également de lutter contre, révélant parfois des résultats auxquels on ne s’attendait pas, et qui nous obligent à regarder nos sources sous un jour nouveau.
- développement d’un outil de découvertes. Les méthodes quantitatives, notamment celles que nous présentons ici, sont tout autant (voire plus) un outil de “découverte” qu’un outil de “preuve”. L’utilisation de ces méthodes permet de s’approprier son corpus et d’en observer les caractéristiques principales, d’une manière que ne permettent pas des analyses plus qualitatives. Elles permettent également de dégager quelques tendances propres à stimuler une réflexion plus globale sur son sujet de recherche.
- nécessité du croisement des méthodes. Encore plus vrai pour l’historien: les sources dont on dispose sont toujours partielles. L’historien s’efforce de reconstruire une histoire fidèle de la discipline, avec les moyens et les données dont il dispose. Le croisement des méthodes (analyse de différentes sources textuelles, interview quand c’est possible, et méthodes quantitatives) permet de combler certains trous et de croiser les perspectives d’analyse.
- volonté des historiens et épistémologues/philosophes d’être des “généralistes” (Trautwein 2017). Avec la multiplication des publications en économie depuis 50 ans, il est impossible de lire tous les travaux importants en économie. Même les historiens se voient obligés de se spécialiser dans différentes branches de l’économie récente. Les méthodes quantitatives constituent une manière de construire des ponts entre les différentes spécialités de l’économie, et de tenter de garder en vue une perspective plus générale sur l’évolution de l’économie (sans pour autant réduire son analyse à l’étude d’un ou quelques “grands” auteurs).
- mettre au centre les “méthodes” et “pratiques” de recherche. Si les analyses quantitatives attirent souvent des reproches par rapport à ce qu’elles sont capables de produire, leur utilisation impose donc d’être attentif aux hypothèses de recherche, choix des outils, à ce qu’on peut dire avec ces méthodes ou non, etc. On peut alors espérer que ce type de questionnements, trop peu souvent abordé pour les travaux non-quantitatifs, se généralisent et poussent les chercheurs en HPE/Philo éco à développer leur réflexivité.
Nous avons parlé jusqu’ici de “méthodes quantitatives”, mais cette expression est extrêmement réductrice: ces méthodes sont en fait plurielles et s’intéressent à des questions très différentes. Il est également important de faire la distinction entre les sources ou données, qui permettent l’utilisation de ces méthodes, et les méthodes elles-mêmes. Même s’il existe des “base de données”, il y a souvent, dans tout un projet de recherche, un travail important à effectuer sur ces données. Pour l’historien, la construction de ses propres données est parfois un passage obligé.
Les différentes sources de données pour les méthodes quantitatives :
| Sources | Types de données | Base de données & Extraction | Exemples d’utilisation |
|---|---|---|---|
| Données bibliographiques | Auteurs, date de publication, revue, affiliations des auteurs, références citées… | Web of Science ; Scopus ; Dimensions ; extraction manuelle, ou semi-automatique via anystyle | Claveau et Gingras (2016); Claveau et Dion (2018); Goutsmedt (2021); Heilbron et Gingras (2018) |
| Données Prosopographiques (ou biographie collective) | lieu et date des diplômes, positions occupées, participation à des associations | Extraction manuelle: CV et informations diverses sur internet. Extraction automatisée : utilisation du web-scrapping Population : participants d’une conférence, membres d’une association ou d’une université… | Goutsmedt, Renault, et Sergi (2021), Svorenčík (2018), Lemercier et Picard (2012), Hoover et Svorenčík (2020) |
| Données textuelles (texte brut) | Mots et agencement des mots dans le texte | Text-mining : extraction du texte brut (après usage de l’OCR) | Johnson, Arel-Bundock, et Portniaguine (2019), Ibrocevic et Thiemann (2018) |
| Données diverses | Projets soumis à des fonds de recherche, correspondance entre auteurs | Extraction manuelle ou automatisée. Web-scrapping, outil essentiel pour extraire des données sur le web | The Republic of Letters Project |
Les différentes méthodes applicables à ces sources :
| Méthodes | Sources | Type de méthodes | Logiciel/outils | Exemples d’utilisation |
|---|---|---|---|---|
| Statistiques Descriptives | Tout type | fréquence, tri croisé… | Excel, langage de programmation (R, Python) | Claveau et Dion (2018), Truc et al. (2020), Hoover et Svorenčík (2020) |
| Test statistiques, Econométrie et Machine Learning | Tout type | régressions, chi, Analyse à composantes multiples, analyse séquentielle, algorithme de classification | Stata, SAS, langage de programmation | Cherrier et Saïdi (2015) Goutsmedt (2021) Angrist et al. (2017) |
| Analyse de textes assistée par ordinateur | Données textuelles | Léxicométrie, Topic-modelling, analyse de sentiments | IRaMuTeQ, TXM, Voyanttools, langage de programmation | Mohr et Bogdanov (2013), Ambrosino et al. (2018), Malaterre, Chartier, et Pulizzotto (2019) |
| Bibliométrie | Données bibliométrique | H-index, statistiques de co-écriture, de sujets/thématiques, couplage et co-citation | Excel, langage de programmation | Truc, Claveau, et Santerre (2021), Claveau et Gingras (2016), Goutsmedt (2021) |
| Analyse de réseaux | Plutôt données bibliométriques et prosopographiques | couplage et co-citation, statistiques de réseau (degré, intermédiarité…), partitionnement | GEPHI, langage de programmation | Herfeld et Doehne (2019), Helgadóttir (2016) |
1er exemple de méthode: la léxicométrie
2ème exemple: Bibliométrie et analyse de réseaux
De quoi parle-t-on quand on parle de bibliométrie?
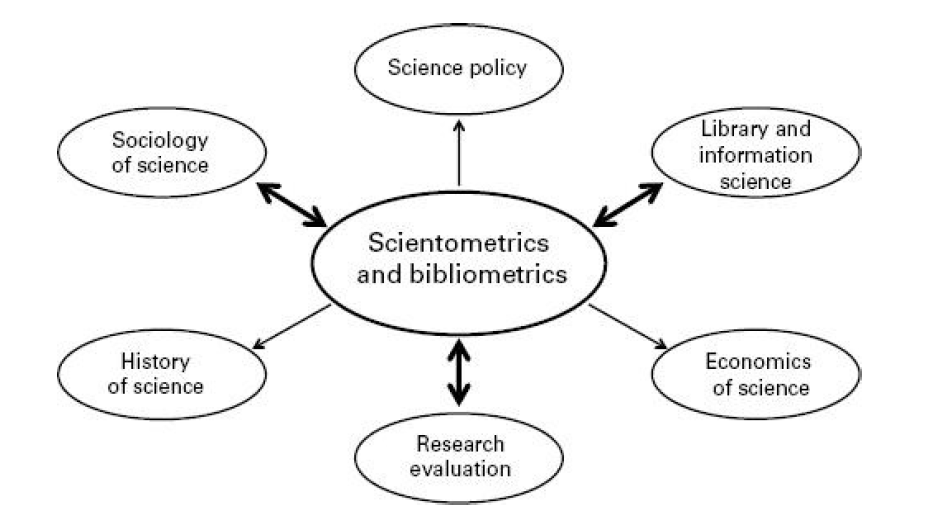
La bibliométrie peut être considéreée comme une sous-branche de la scientométrie, c’est-à-dire la discipline qui mesure la production de la science. Au fondement de la bibliométrie se trouve la mesure du nombre de publications scientifiques d’une entité donnée (individu, institution, pays…), et le nombre de citations reçu par cette entité (voir l’introduction de Gingras 2016).
La bibliométrie a avant tout été conçu comme un outil d’évaluation de la productivité d’un chercheur ou d’une institution. La bibliométrie a aussi pour but, par exemple, d’évaluer la diffusion des articles publiés par une revue (par exemple avec l’impact factor).
Au-delà de cette perspective normative et managériale, la bibliométrie peut constituer un outil intéressant pour les sciences sociales et notamment l’histoire de la pensée et la philosophie économique (voir Figure sur l’usage de la bibliométrie).
- faire un état de lieux aujourd’hui ou à différentes époques d’une discipline, sous-displine ou d’une thématique particulière;
- explorer des traditions et héritages, en regardant notamment quels travaux du passé inspirent les travaux d’aujourd’hui;
- étudier les relations et transferts disciplinaires;
- croisement avec des questions plus sociologiques et institutionnelles, en étudiant les collaborations entre différentes institutions ou pays.
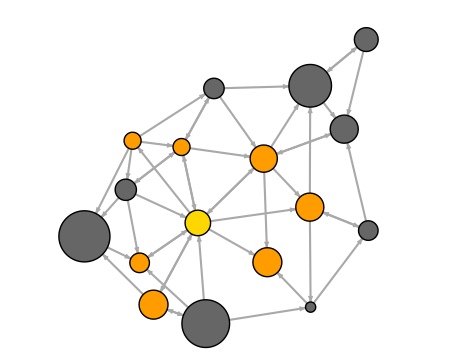
Et qu’est-ce l’analyse de réseau vient faire là-dedans
Un réseau est une structure constituée de deux types d’éléments: des noeuds (nodes ou vertices) et des liens (edges) qui relient ces noeuds entre eux (voir l’exemple de la figure).
L’analyse de réseau peut être appliquée à la bibliométrie à travers plusieurs types d’analyses. Par exemple, à travers les réseaux de coécritures, où les noeuds sont des auteurs, et les liens des collaborations dans l’écriture de publications scientifiques (Kumar 2015).
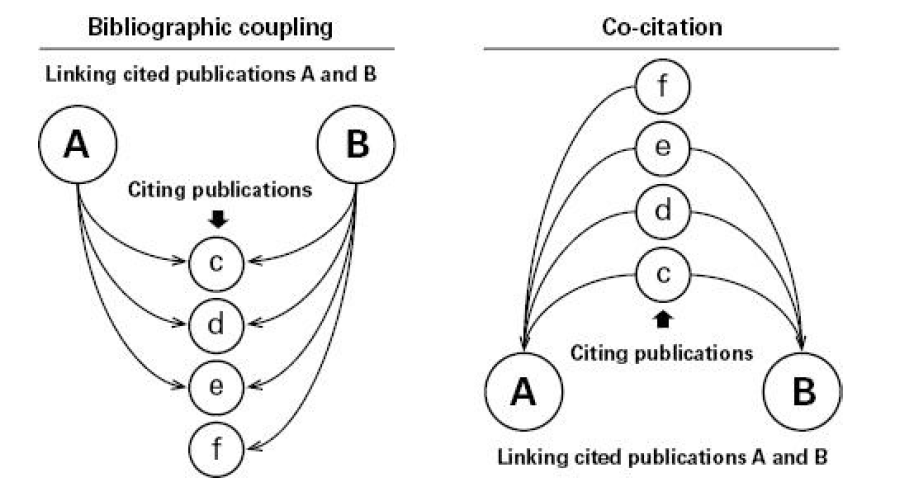
Nous allons nous intéresser ici à deux autres types de réseaux: les réseaux de couplage bibliographique et les réseaux de co-citations (voir la figure ):
- La première méthode part des articles “citant” qui vont être les noeuds du réseau. On s’intéresse à leur proximité en fonction du nombre de références qu’ils ont en commun dans leur bibliographie. Par exemple si deux articles ont trois références en commun, ils ont un lien d’une valeur de 3 entre eux (il existe en fait différentes techniques de pondération pour prendre en compte la taille des bibliographies de chaque article, ainsi que l’importance de chaque référence en commun).
- La co-citation part des articles cités qui sont les noeuds du réseau. On s’intéresse au nombre de fois où ces articles se retrouvent cités ensemble. Autrement dit, combien de fois deux références se retrouvent-ils ensemble. Si on reprend l’exemple ci-dessus, les trois références citées ensemble par les articles A et B ont donc un lien de 2 les uns avec les autres (ils sont dans la bibliographie de A, et dans celle de B).
Cas pratique 2021: le projet Macro-histoire de la macroéconomie
Brève introduction du projet
Le projet Macro-Histoire de la macroéconomie est un projet financé par l’History of Economics “New Initiatives Fund”. Il vise, dans un premier temps, à produire une histoire bibliométrique des grandes évolutions de la macroéconomie depuis les années 1970. Dans un second temps, une plateforme interactive et dynamique sera créée pour diffuser les résultats obtenus1.
La motivation fondamentale pour ce projet vient de mon travail de thèse, qui s’intéressait aux transformations de la macroéconomie dans les années 1970. On parle souvent pour décrire cette période de révolution de la nouvelle économie classique, et on insiste sur la remise en cause totale de la macroéconomie keynésienne. Dans mon travail de thèse, j’essayais de multiplier les points de vue et de déplacer le regard (travaux des auteurs moins connus, étude des proceedings de conférences, étude des travaux empiriques) pour questionner l’ampleur et la dynamique de ces transformations de la macroéconomie. Cela me permettait d’insister sur le fait que ces transformations étaient moins radicales et moins soudaines que ce que ne le laissait penser l’historiographie standard.
Mais cette volonté de questionner la manière dont les économistes eux-même racontent leur propre histoire se heurte à une angoisse: celle d’être capable d’évaluer et de carthographier ce que produit un vaste champ de recherche à un instant t. Et c’est ce qui motive ce projet bibliométrique:
- être capable d’évaluer les différentes spécialités d’un champ tel que la macro à une certaine période, ainsi que le poids de ces spécialités;
- Comment ces spécialités et leur poids respectifs évoluent au cours du temps;
- Quelles spécialités sont les plus proches et les plus éloignées;
- Quelle est l’importance de certains articles ou certains auteurs à différents moments de l’histoire.
La première étape de ce projet a été de constituer notre corpus de la macroéconomie. Nous utilisons deux méthodes pour constituer ce corpus, et notre objectif est de comparer les résultats avec ces deux méthodes. Pour ce cours, nous allons nous intéresser uniquement à la méthode la plus simple. Grâce à la base de données “Econlit”, nous avons recensé tous les articles avec un JEL code macroéconomie. Assez simple après 1991, car on a un JEL code spécifique, le E (même si on intègre F3 et F4 pour avoir la macro internationale). Plus compliquée avant 1991, où il faut utiliser un tableau de correspondance entre l’ancienne et la nouvelle catégorisation (JEL 1991).
Pour l’exercice suivant, nous allons prendre des données de la période 1970-1976. La segmentation des données permet d’étudier des évolutions historiques, d’avoir des corpus qui ne sont pas trop gros (principalement pour des questions de tractabilité), mais surtout d’éviter un triple biais de construction énorme:
- Le corpus n’est pas distribué de manière similaire au cours du temps: on a de plus en plus d’articles plus on avance dans le temps (accroissement du nombre de publication en économie + biais de construction de la base de données de l’OST reposant sur WoS).
- Les articles les plus récents ont tendance à avoir des bibliographies plus conséquentes.
- On tend à citer des articles qui ont été publiés récemment, et pas de vieux articles.
La conséquence de cela est que des réseaux qui s’étaleraient sur trente/quarante ans seraient surdéterminés par les articles les plus récents, et les travaux les plus anciens seraient invisibilisés.
Exemple pratique: manipuler les données sur GEPHI
On va travailler ici sur un jeu de données composé de deux fichiers:
- un fichier de nœuds, avec une liste d’articles citant. Dans ce tableau, on trouvera des infos sur l’auteur (le premier auteur), le titre, la date de publication, la revue.
- un fichier de liens, qui matérialise les liens entre différents nœuds/articles, en fonction des références qu’ils ont en commun dans leur bibliographie.
1ère étape: télécharger et installer GEPHI
La première étape consiste à télécharger et installer le logiciel GEPHI (sur la page de GEPHI, cliquer sur le bouton “Download Free”, puis sélectionner le téléchargement correspond à votre système d’exploitation). Un guide d’initiation est téléchargeable sur le site.
GEPHI est un logiciel d’analyse de réseau codé en JavaScript. Il permet d’importer vos données de réseaux, notamment en .csv (un certain type de fichier pour stocker vos tableurs excel), de visualiser vos réseaux, et d’effectuer un certain nombre de manipulation sur ces réseaux.
2ème étape: importer vos données
Téléchargez d’abord les données partielles (pour s’entraîner) des noeuds et des liens.
Dans l’onglet File, cliquer sur Import spreadsheet (“importer feuille de calcul”). Commencer par importer les noeuds (“nodes.csv”). S’affiche alors une fenêtre intitulée “General CSV options (1 of 2)”. Vérifier que les données s’affichent correctement en colonne, puis vérifier que le fichier soit importé (Import as) comme “Nodes table” (tableau des noeuds). Vous pouvez cliquer sur Next. Vous êtes désormais à la deuxième étape de l’importation, “Import settings (2 of 2)” où vous pouvez choisir les colonnes à importer. Importez toutes les colonnes, et cliquer sur finish.
Une nouvelle fenêtre s’est ouverte. Changer le Graph Type qui est par défault sur “Mixed” (“Mélangé”) par “Undirected” (“Non dirigé”). En effet, les liens entre deux noeuds matérialisent la part des références qu’ils ont en commun. Les liens ne sont donc en aucun cas dirigés (ce qui est différent, par exemple, d’un réseau de citation directe, où un noeud cite un autre noeud). Ensuite, cocher l’option “Append to existing workspace”, puis cliquez sur ok.
Vos 1862 noeuds (qui représentent les 1862 articles avec un JEL code de macroéconomie, recensés dans WoS) s’affichent désormais. Ils ont été disposés de manière aléatoire. Il faut désormais importer les liens (“edges.csv”) et on répète la procédure. Dans la fenêtre “General CSV options”, vérifiez que “Edges table” s’affiche sous Import as, puis cliquez sur Next. Vérifiez que les “weights” des liens sont bien enregistrés sous le format “Double” (qui permet de prendre en compte plusieurs chiffres après la virgule). Cliquez sur Finish. Dans la nouvelle fenêtre, comme pour l’importation des noeuds, indiquez que le réseau est “Undirected” et cochez “Append to existing workspace”.
Vous avez désormais votre réseau avec vos 1862 noeuds et les 14397 liens qui les relient entre eux. On dit que ce réseau forme une “composante principale”, car à partir de n’importe quel noeud, il est possible de rejoindre n’importe quel autre noeud. Autrement dit, aucun noeud ou aucun groupe de noeud n’est détaché du reste du réseau. Dans le prétraitement des données, je n’ai en effet gardé que la composante principale. Mais les composantes secondaires sont assez rares et assez petites dans les réseaux de couplage bibliographique.
3ème étape: la spatialisation
La première chose à faire est d’utiliser un “layout”, c’est-à-dire un algorithme de spatialisation qui va calculer des coordonnées aux noeuds, en fonction de leurs liens entre eux. La plupart des algorithmes de spatialisation proposé par GEPHI (dans le panneau en bas à gauche) sont des algorithmes dit “force-based”. Ils reposent sur deux principes fondamentaux: les noeuds reliés sont attirés les uns vers les autres (plus ou moins fortement suivant la force du lien), les noeuds non reliés sont éloignés les uns des autres. Nous allons utiliser l’algorithme Force Atlas 2 (Jacomy et al. 2014) qui produit une spatialisation de type cartographique. Les noeuds vont être regroupés comme des continents, tout en s’étalant dans l’espace.
Sélectionnez le layout Force Atlas 2. Fixez le paramètre de scaling (à 2 par défaut) à 0.5 pour réduire l’échelle d’étalement du réseau. Lancez Run puis cliquez sur Stop une fois les mouvements des noeuds devenus infimes. On voit déjà apparaître certains groupes de noeuds relativement proches, témoignant d’une certaine proximité en termes de citations. Apparaît également une structure centre/périphérie, avec un groupe dense mais éloigné du coeur du graph.
4ème étape: le partitionnement du réseau
Nous allons ensuite créer une partition de notre réseau, c’est-à-dire que nous allons répartir les noeuds dans différents groupes, en fonction des liens qu’ils partagent entre eux. Le but est de repérer des “communautés” qui partagent un ou des objets de recherche relativement communs. Pour cela, nous utilisons un algorithme de partitionnement qui repose sur la maximisation de la modularité. Il s’agit de maximiser la densité des liens intra-groupes et de minimiser la densité des liens inter-groupes. Nous allons pour cela utiliser l’algorithme de Louvain (De Meo et al. 2011).
Dans GEPHI, allez dans le panneau statistics en bas à droite, et cliquez sur run pour la statistique de “Modularity”. Il s’agit en fait de la méthode de Louvain. Vérifiez que “use weights” est bien coché, puis fixez la résolution à 2. Cela nous permettra de diminuer le nombre de communauté et de facilité l’analyse. Apparaît une nouvelle fenêtre avec le nombre de communautés identifiées et la taille de ces communautés. A chaque noeud correspond désormais un numéro de communauté (ou “Modularity Class”)2.
5ème étape: soigner la visualisation
Il s’agit désormais de faire apparaître plus clairement les informations sur le graphique. Allons pour cela dans le panneau “Appearance”, et restez sur l’onglet “Nodes”. Cliquez sur la petite palette de peinture juste à droite de Nodes/Edges (si vous n’y êtes pas déjà). Cliquez ensuite sur l’onglet Partition. Choisissez “Modularity Class” comme attribut, et cliquez sur Apply. Désormais, chaque noeud a une couleur qui est fonction de sa communauté, identifiée par Louvain.
Allons ensuite modifier la taille des noeuds, en cliquant sur les cercles concentriques, juste à droite de la palette (Toujours dans “Appearance”, “Nodes”). Allez dans Ranking et choisissez “nb_cit” comme attribut. Il s’agit du nombre de fois où un noeud a été cité par les autre articles du corpus. Prenez 10 comme valeur minimale, et 100 comme valeur maximale. Pour éviter que les noeuds se chevauchent, vous pouvez retourner dans layout et choisir l’algorithm “Noverlap”. Cliquez sur Run et pensez à arrêter l’algorithme ensuite.
Dernière étape, en dessous du réseau, cliquez sur le grand T en noir, pour afficher les étiquettes des noeuds. Nous allons ensuite modifier la taille de ces étiquettes pour rendre le graph plus lisible. Retournez dans “Apperance”, “Nodes” et cliquez sur les deux T. Sélectionnez Ranking puis “nb_cit”. Prenez 0.1 comme taille minimale, puis 3.5 comme taille maximale. Dans “Layout”, utilisez “Label Adjust” pour éviter l’enchevêtrement d’étiquettes.
Voilà vous avez créé votre réseau de couplage bibliographique des articles de macroéconomie entre 1970 et 1976. Vous pouvez désormais, grâce à Gephi, explorer votre réseau. Vous pouvez désormais vous amusez en changeant la visualisation, en changeant de paramètrage pour la spatialisation (ou de type de spatialisation) et le partitionnement.
Pour vous entraîner, vous pouvez reproduire le même processus avec les données sur la même période, mais pour la cocitation, en téléchargeant les noeuds et les liens.
6ème étape: Que fait-t-on de ce que l’on voit?
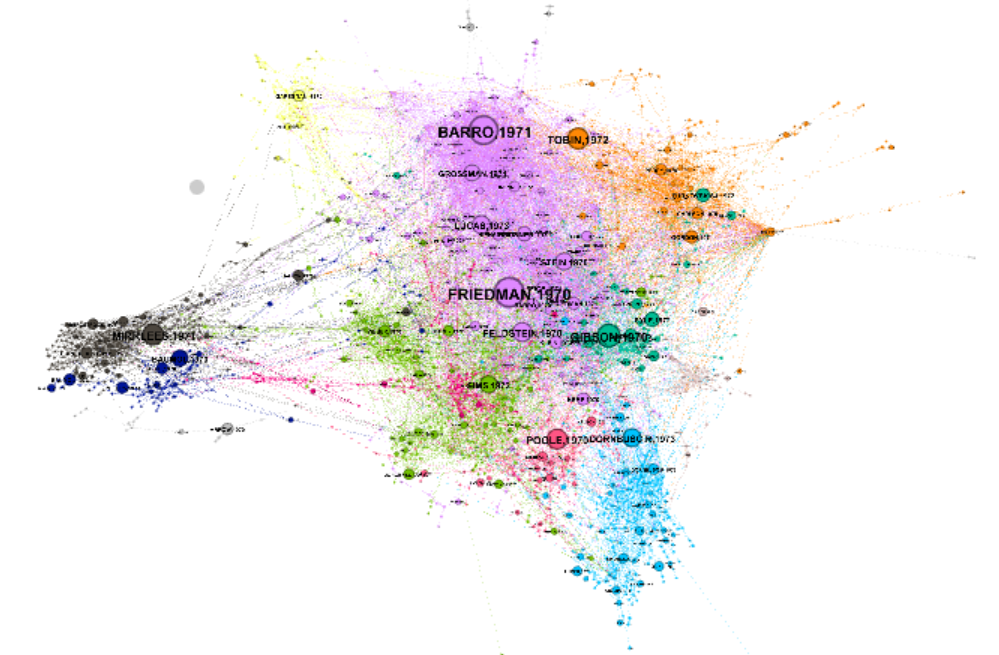
L’analyse de réseau passe en partie par la projection graphique, qui donne à voir des éléments factuels via la disposition dans l’espace des noeuds. La visualisation de réseau ne peut être une preuve directe, mais elle synthétise des éléments d’information qui peuvent conduire à une enquête plus poussée. La visualisation graphique est également un outil d’exploration (par le zoom et l’étude des liens, quand les réseaux sont interactifs, on peut voir quels sont les articles importants, avec qui ils partagent le plus de liens, etc.).
On a trois faisceaux d’indices qui ressortent de l’analyse d’un réseau:
- la disposition centre-périphérie, qui établit ce qui va être au coeur de la discipline, et les travaux plus périphériques, qui partagent moins de liens avec les autres.
- la taille des communautés, via le nombre de noeuds qui les composent.
- la proximité des communautés entre elles. Cet élement est cependant à prendre avec des pincettes, car le positionnement des noeuds (et donc des communautés) est le jeu d’un processus complexe d’attraction et de répulsion. Deux communautés peuvent être proches, non pas parce qu’elles partagent beaucoup de liens entre elles, mais parce qu’elles partagent beaucoup de liens avec les mêmes communautés, ce qui les place à proximité.
Quelles étapes ensuite?
Une première étape consiste à étudier plus précisément la composition de ces communautés. C’est ici qu’une analyse plus qualitative accompagne le quantitatif: il s’agit de comprendre ce que représente chaque communauté, notamment pour pouvoir l’identifier et la nommer.
Dans un premier temps, on met en avant un certain nombre de données sur chaque communauté (références les plus citées, affiliations et revues récurrentes, mots les plus utilisés dans les titres, etc.). On analyse ces données, et on poursuit l’analyse en allant regarder de plus près certains articles (quand on a pas déjà une idée précise de ce dont il s’agit). On établit ensuite une catégorisation cohérente pour nommer les communautés.
Une deuxième étape consiste ensuite à analyser de manière plus précise les relations entre les communautés, en construisant des indicateurs de proximité, pour étudier les communautés les plus “autonomes” (celles qui sont le moins reliées aux autres, et qui ont donc un objet d’étude relativement indépendant, éloigné des autres communautés), et celles qui partagent le plus de références. Cette analyse au niveau du couplage bibliographique peut être complété en étudiant les liens entre le réseau de couplage et le réseau de co-citation, notamment en étudiant quelles communautés de co-citation sont citées par quelles communautés de couplage.
Une troisième étape consiste à pousser l’analyse en “dynamique”, en étudiant l’évolution dans le temps de nos différentes catégories.
Cas pratique 2022: les articles utilisant des modèles DSGE (via Scopus)
La première étape consiste à se connecter à la plateforme scopus et à télécharger les métadonnées des articles utilisant les termes “DSGE” ou “Dynamic Stochastic General Equilibrium” dans leur titre, leurs mots clés, ou leur abstract. Vous trouverez plus d’information sur comment télécharger ces données dans le tutoriel suivant.
Une fois ces données obtenues, vous pouvez les manipuler et les nettoyer via le “Notebook” R suivant3. Vous pouvez le télécharger en cliquant sur le petit onglet “code” en haut à gauche puis sur “Download Rmd”. Cela vous permettra d’obtenir les nœuds et les liens de votre réseau de co-citation, que vous pourrez dès lors exporter et utiliser sur GEPHI, en utilisant les instructions ci-dessus. Il est toutefois possible de continuer sur R plutôt que d’utiliser GEPHI, que ce soit pour créer le réseau, identifier des communautés, spatialiser les nœuds ou les projeter. Ce tutoriel vous y aidera.
3ème exemple: les statistiques multidimensionnelles appliquées à l’histoire de la pensée économique
Cas pratique animé par Julien Gradoz en 2022 (slides ici).
Quelques ressources utiles
The Programming Historian
Le site Programming Historian offre un ensemble de tutoriels utiles pour les chercheurs en sciences sociales, allant du web-scraping à l’analyse de réseau ou au text-mining. Vous y trouverez également des tutoriels intéressant sur:
- Au web-scraping;
- Au nettoyage de données en utilisant les expressions régulières;
- comment passer l’OCR en série;
- (et même) comment changer de pratiques d’écritures et les supports de cette écriture avec pandoc.
GEPHI
Vous trouverez tout un ensemble de tutoriels pour Gephi sur cette page. Je vous conseille également le tutoriel réalisé par Martin Grandjean sur son blog, qui est assez bien fait.
Initiation à R
Vous trouvez des indications nombreuses de lectures et de ressources pour apprendre R ici. Brièvement, signalons:
Une bonne introduction aux bases de R et à l’une des séries de packages les plus populaire, “tidyverse”, est disponible ici. Vous y apprendrez comment utiliser Rstudio, les objets de base, puis vous serez guidé pas à pas pour faire de l’analyse statistique.
Si vous vous sentez en confiance et que vous avez envie de monter un peu l’exigence, R for Data Science constitue une deuxième étape intéressante. Ici, le niveau s’élève, mais vous apprendrez les bonnes pratiques sur l’écriture de script en R, et le but est de diminuer le plus possible l’effet boîte noire (il s’agit de comprendre le plus possible le code que vous écrivez).
Pour ceux et celles qui veulent aller voir ensuite du côté du text-mining, vous trouverez de quoi apprendre la base rapidement ici.
Pour apprendre les bases de l’analyse de réseaux sociaux, voici un site un peu à l’ancienne mais fait par des spécialistes, et qui permet également de faire tourner du code R. Il repose sur l’utilisation de igraph, l’un des packages fondamentaux de R pour faire de l’analyse de réseau. Enfin, quand vous sentirez plus à l’aise avec R et maîtriserez les bases de l’analyse de réseau, vous pouvez allez jeter un coup d’œil (et surtout utiliser!) les deux packages R que nous avons créé avec Alexandre Truc: biblionetwork et networkflow.
Glossaire
Algorithme Force-based
Les algorithmes de visualisation de réseau par la force sont une classe d’algorithmes permettant de dessiner des graphes d’une manière esthétique. Leur but est de positionner les noeuds d’un graphe dans un espace bidimensionnel ou tridimensionnel de sorte que tous les liens soient plus ou moins de même longueur et qu’il y ait le moins de liens croisés possible, en assignant des forces entre l’ensemble des liens et l’ensemble des noeuds, en fonction de leurs positions relatives, et en utilisant ensuite ces forces pour déplacer les noeuds.
Analyse de réseau/théorie des réseaux
La théorie des réseaux est l’étude de graphes en tant que représentation d’une relation symétrique ou asymétrique entre des objets. Elle s’inscrit dans la théorie des graphes : un réseau peut alors être défini comme étant un graphe où les noeuds (sommets) et/ou les arêtes/liens (ou « arcs », lorsque le graphe est orienté) ont des attributs, comme une étiquette. La théorie des réseaux trouve des applications dans diverses disciplines incluant la physique statistique, la physique des particules, l’informatique, le génie électrique, la biologie, l’économie, la finance, la recherche opérationnelle, la climatologie ou les sciences sociales. Il existe de nombreux types de réseaux : réseau logistique, World Wide Web, Internet, réseau de régulation génétique, réseau métabolique, réseau social, réseau sémantique, réseau de neurones, etc.
Bibliométrie
La bibliométrie est l’analyse quantitative de l’activité et des réseaux scientifiques. Cette discipline, qui s’appuie sur l’analyse statistique des données et des réseaux, a un volet cognitif, en interaction avec les champs se donnant les sciences et les communautés scientifiques comme objet (économie de la connaissance, sociologie des sciences, épistémologie, histoire des sciences, etc.) et avec les sciences de l’information. Elle a un volet opérationnel, en liaison avec l’évaluation, le positionnement des acteurs et le management scientifique.
Léxicométrie
La lexicométrie est l’étude quantitative du lexique, à l’aide de méthodes statistiques.
Modularité
La modularité est une mesure du partitionnement des réseaux ou des graphiques. Elle a été conçue pour mesurer la force de division d’un réseau en modules (également appelés groupes, grappes ou communautés). Les réseaux à haute modularité ont des connexions denses entre les noeuds au sein des modules mais des connexions éparses entre les nœuds des différents modules. La modularité est souvent utilisée dans les méthodes d’optimisation pour détecter la structure des communautés dans les réseaux.
OCR (Optical Character Recognition)
L’OCR désigne les procédés informatiques pour la traduction d’images de textes imprimés ou dactylographiés en fichiers de texte. Un ordinateur réclame pour l’exécution de cette tâche un logiciel d’OCR. Celui-ci permet de récupérer le texte dans l’image d’un texte imprimé et de le sauvegarder dans un fichier pouvant être exploité dans un traitement de texte pour enrichissement, et stocké dans une base de données ou sur un autre support exploitable par un système informatique.
Partitionnement de réseaux
En théorie des graphes et en algorithmique, le partitionnement de graphe est la tâche qui consiste à diviser un graphe orienté ou non orienté en plusieurs parties. Plusieurs propriétés peuvent être recherchées pour ce découpage, par exemple on peut minimiser le nombre de liens reliant deux parties différentes.
Prosopographie
La prosopographie est une méthode qui étudie et inventorie les personalitées qui composent un milieu sociale, avec des notices individuelles construites sur le même modèle, afin d’en mettre en évidence les aspects communs. Pour les historiens, la prosopographie a longtemps été une science auxiliaire de l’histoire dont l’objectif était d’étudier les biographies des membres d’une catégorie spécifique de la société, le plus souvent des élites sociales ou politiques, en particulier leurs origines, leurs liens de parenté, leur appartenance à des cercles de conditionnement ou de décision.
Text_mining
Le text-mining désigne un ensemble de traitements informatiques consistant à extraire des connaissances selon un critère de nouveauté ou de similarité dans des textes produits par des humains pour des humains. Dans la pratique, cela revient à mettre en algorithme un modèle simplifié des théories linguistiques dans des systèmes informatiques d’apprentissage et de statistiques, et des technologies de compréhension du langage naturel.
Web-scraping
Le web-scraping désigne un ensemble de traitements informatiques pour extraire des données recensées sur des pages webs.
Bibliographie
Ambrosino, Angela, Mario Cedrini, John B. Davis, Stefano Fiori, Marco Guerzoni, et Massimiliano Nuccio. 2018. « What Topic Modeling Could Reveal about the Evolution of Economics ». Journal of Economic Methodology 25 (4): 329‑48. https://doi.org/10.1080/1350178X.2018.1529215.
Angrist, Joshua, Pierre Azoulay, Glenn Ellison, Ryan Hill, et Susan Feng Lu. 2017. « Economic Research Evolves: Fields and Styles ». American Economic Review 107 (5): 293‑97.
Backhouse, Roger E. 1998. « The Transformation of U.S. Economics, 1920-1960, Viewed through a Survey of Journal Articles ». History of Political Economy 30 (4): 85‑107. http://search.ebscohost.com/login.aspx?direct=true&db=bth&AN=7752166&lang=fr&site=ehost-live.
Cherrier, Beatrice, et Aurélien Saïdi. 2015. « The Indeterminate Fate of Sunspots in Economics ». SSRN Scholarly Paper ID 2684756. Rochester, NY: Social Science Research Network.
Cherrier, Beatrice, et Andrej Svorenčík. 2018. « The Quantitative Turn in the History of Economics: Promises, Perils and Challenges ». Journal of Economic Methodology 0 (0): 1‑11. https://doi.org/10.1080/1350178X.2018.1529217.
Claveau, François, et Jérémie Dion. 2018. « Quantifying Central Banks’ Scientization: Why and How to Do a Quantified Organizational History of Economics ». Journal of Economic Methodology 0 (0): 1‑18. https://doi.org/10.1080/1350178X.2018.1529216.
Claveau, François, et Yves Gingras. 2016. « Macrodynamics of Economics: A Bibliometric History ». History of Political Economy 48 (4): 551‑92.
De Meo, Pasquale, Emilio Ferrara, Giacomo Fiumara, et Alessandro Provetti. 2011. « Generalized Louvain Method for Community Detection in Large Networks ». In 2011 11th International Conference on Intelligent Systems Design and Applications, 88‑93. IEEE.
Edwards, José, Yann Giraud, et Christophe Schinckus. 2018. « A Quantitative Turn in the Historiography of Economics? » Journal of Economic Methodology 25 (4): 283‑90. https://doi.org/10.1080/1350178X.2018.1529133.
Gingras, Yves. 2016. Bibliometrics and Research Evaluation: Uses and Abuses. The MIT Press. https://direct.mit.edu/books/book/4081/bibliometrics-and-research-evaluationuses-and.
Goutsmedt, Aurélien. 2021. « From the Stagflation to the Great Inflation: Explaining the US Economy of the 1970s ». Revue d’Economie Politique Forthcoming. https://mega.nz/file/zfJ2QBbb#3OqXBIQRYmuQzptMyfvwW92IXhN-pWApKpILSs_w-pg.
Goutsmedt, Aurélien, Matthieu Renault, et Francesco Sergi. 2021. « European Economics and the Early Years of the International Seminar on Macroeconomics ». Revue d’Economie Politique Forthcoming 2021.
Heilbron, Johan, et Yves Gingras. 2018. « The Globalization of European Research in the Social Sciences and Humanities (1980): A Bibliometric Study ». In The Social and Human Sciences in Global Power Relations, 29‑58. Springer.
Helgadóttir, Oddny. 2016. « The Bocconi Boys Go to Brussels: Italian Economic Ideas, Professional Networks and European Austerity ». Journal of European Public Policy 23 (3): 392‑409.
Herfeld, Catherine, et Malte Doehne. 2018. « Five Reasons for the Use of Network Analysis in the History of Economics ». Journal of Economic Methodology 25 (4): 311‑28. https://doi.org/10.1080/1350178X.2018.1529172.
———. 2019. « The Diffusion of Scientific Innovations: A Role Typology ». Studies in History and Philosophy of Science Part A 77 (octobre): 64‑80. http://www.sciencedirect.com/science/article/pii/S0039368117303321.
Hoover, Kevin D., et Andrej Svorenčík. 2020. « Who Runs the AEA? » SSRN Scholarly Paper ID 3741439. Rochester, NY: Social Science Research Network. https://papers.ssrn.com/abstract=3741439.
Ibrocevic, Edin, et Matthias Thiemann. 2018. « All Economic Ideas Are Equal, but Some Are More Equal Than Others: A Differentiated Perspective on Macroprudential Ideas and Their Implementation ». SSRN Electronic Journal. https://www.ssrn.com/abstract=3195910.
Jacomy, Mathieu, Tommaso Venturini, Sebastien Heymann, et Mathieu Bastian. 2014. « ForceAtlas2, a Continuous Graph Layout Algorithm for Handy Network Visualization Designed for the Gephi Software ». PloS one 9 (6): e98679.
JEL. 1991. « Classification System: Old and New Categories ». Journal of Economic Literature 29 (1): xviii‑xxviii. https://www.jstor.org/stable/2727351.
Johnson, Juliet, Vincent Arel-Bundock, et Vladislav Portniaguine. 2019. « Adding Rooms onto a House We Love: Central Banking after the Global Financial Crisis ». Public Administration 97 (3): 546‑60.
Kumar, Sameer. 2015. « Co-Authorship Networks: A Review of the Literature ». Aslib Journal of Information Management, janvier. https://www.emerald.com/insight/content/doi/10.1108/AJIM-09-2014-0116/full/html.
Lemercier, Claire, et Emmanuelle Picard. 2012. « Quelle Approche Prosopographique? »
Malaterre, Christophe, Jean-François Chartier, et Davide Pulizzotto. 2019. « What Is This Thing Called Philosophy of Science? A Computational Topic-Modeling Perspective, 1934 ». HOPOS: The Journal of the International Society for the History of Philosophy of Science 9 (2): 215‑49.
Mohr, John W., et Petko Bogdanov. 2013. « Introduction Models: What They Are and Why They Matter ». Poetics, Topic Models et the Cultural Sciences, 41 (6): 545‑69. http://www.sciencedirect.com/science/article/pii/S0304422X13000685.
Svorenčík, Andrej. 2018. « The Missing Link: Prosopography in the History of Economics ». SSRN Scholarly Paper ID 3168790. Rochester, NY: Social Science Research Network. https://papers.ssrn.com/abstract=3168790.
Trautwein, Hans-Michael. 2017. « The Last Generalists ». The European Journal of the History of Economic Thought, 1‑33.
Truc, Alexandre, François Claveau, et Olivier Santerre. 2021. « Economic Methodology: A Bibliometric Perspective ». Journal of Economic Methodology, janvier, 1‑12. https://www.tandfonline.com/doi/full/10.1080/1350178X.2020.1868774.
Truc, Alexandre, Olivier Santerre, Yves Gingras, et François Claveau. 2020. « The Interdisciplinarity of Economics ». Available at SSRN.
Une plateforme de ce type a été produite en 2016 par François Claveau, pour l’économie dans son ensemble: http://www.digitalhistoryofscience.org/economics/index.php. ↩︎
Vous pouvez vérifier cela en changeant d’interface principale (vous étiez jusqu’ici dans
Overview) en cliquant surData Laboratory, qui affiche vos données pour les noeuds et les liens. ↩︎Vous trouverez plus d’informations sur ce qu’est un Notebook ici. ↩︎