Moissonner les discours des banquiers centraux à partir du site de la BRI
Scraping Tutorials 1
Table des matières
Moissonner des données
Dans ce billet, vous apprendrez comment récupérer les discours de la [base de données des discours de la Banque des règlements internationaux] (https://www.bis.org/cbspeeches/index.htm?m=256), qui rassemble la plupart des discours des banquiers centraux en anglais. Nous le ferons en programmant en R. Le deuxième tutoriel se concentre sur l’extraction de documents du site web de la Banque centrale européenne et le troisième tutoriel sur l’extraction de documents du site web de la Banque d’Angleterre.
Qu’est-ce que le web scraping ?
Le web scraping est le processus d’extraction de données à partir de sites web. Il s’agit d’accéder de manière programmatique au contenu d’un site web, d’en extraire les données souhaitées et de les sauvegarder en vue d’une utilisation ultérieure. Il s’agit d’accéder à une URL spécifique, de récupérer le contenu html et d’extraire les données souhaitées à partir de ce contenu.
En général, on utilise le web scraping lorsqu’il n’existe pas d’API (Application Programming Interface) pour les données du site web auxquelles vous souhaitez accéder. Une API est un moyen structuré et autorisé d’accéder aux données fournies par un site web, à partir d’un système de requêtes (par exemple, scopus fournit une API pour récupérer ses données bibliométriques).
L’extraction de données d’un site web soulève diverses questions éthiques et juridiques (pour lesquelles je ne suis pas un spécialiste !). Tout d’abord, de nombreux sites web ont des conditions d’utilisation qui interdisent explicitement le web scraping. S’engager dans le scraping sans le consentement du propriétaire du site web constitue une violation de ces termes et conditions. Par exemple, Linkedin interdit le scraping sur son site web. Toutefois, la “légalité” du scraping sur Linkedin reste une question complexe. Avant de vous lancer dans le moissonnage, vous devez connaître les conditions d’utilisation et les risques encourus si vous les enfreignez.
Un deuxième problème concerne la surcharge des serveurs. Le web scraping peut faire peser une charge importante sur les serveurs d’un site web, ce qui peut entraîner une baisse des performances ou des temps d’arrêt. Le moissonnage sans limitation de débit appropriée et sans respect de la capacité d’un site web peut être considéré comme contraire à l’éthique et perturbateur.
Troisièmement, si vous êtes autorisé à explorer un site web, cela ne signifie pas que vous pouvez copier et distribuer le matériel collecté. Vous devez être conscient des droits d’auteur et de propriété intellectuelle lorsque vous diffusez du contenu moissonné.
Quelques ressources utiles
Lorsque l’on parle de web scraping avec R, trois packages R se distinguent (mais nous n’en utiliserons que deux ici) :
- rvest (Wickham 2022) : un package dans l’esprit tidyverse qui permet d’extraire des données de pages web. Il fonctionne mieux avec les pages web statiques (voir ci-dessous).
- RSelenium](https://docs.ropensci.org/RSelenium/) (Harrison 2022) : il s’agit d’un binding R pour Selenium 2.0 Remote WebDriver, qui permet d’automatiser l’utilisation d’un navigateur. En d’autres termes, il vous permet d’écrire un script pour ouvrir un navigateur web et interagir avec un site web (et c’est là que le scraping commence à devenir amusant !).
- polite](https://dmi3kno.github.io/polite/) (Perepolkin 2023) : ce package vous permet de consulter le robots.txt d’un site web pour savoir quelles sont les règles de scraping pour ce site web, et pour éviter de surcharger le site avec trop de requêtes.
En fonction du site web que vous souhaitez moissonner, l’utilisation de rvest peut être suffisant (comme c’est le cas, par exemple, avec Wikipedia). Pour les sites web plus complexes, vous aurez peut-être besoin de RSelenium, en combinaison avec rvest ou seul. En effet, tout dépend si les pages web que vous souhaitez récupérer sont statiques ou dynamiques. Comme l’explique l’article de blog d’Ivan Milanes :
- Page Web statique : Une page web (page HTML) qui contient les mêmes informations pour tous les utilisateurs. Bien qu’elle puisse être mise à jour périodiquement, elle ne change pas à chaque fois que l’utilisateur la consulte.
- Page Web dynamique : Une page Web qui fournit un contenu personnalisé à l’utilisateur en fonction des résultats d’une recherche ou d’une autre requête. Également appelé “HTML dynamique” ou “contenu dynamique”, le terme “dynamique” est utilisé pour désigner les pages Web interactives créées pour chaque utilisateur.
La page web où sont rassemblés les discours des banquiers centraux est une page web dynamique et nous utiliserons donc RSelenium pour extraire les discours.1.
Pour compléter ce tutoriel, vous trouverez deux autres tutoriels utiles sur le scraping à l’aide de rvest et RSelenium ici et ici. Il existe également un chapitre entier consacré au scraping web dans la récente deuxième édition de R for Data Science (Wickham, Çetinkaya-Rundel, and Grolemund 2023).
Moissonner les discours de la BRI
Si nous nous intéressons à ce que disent les banquiers centraux, nous pouvons vouloir étudier leurs discours. Heureusement, la plupart d’entre eux sont stockés sur le site web de la BRI là.
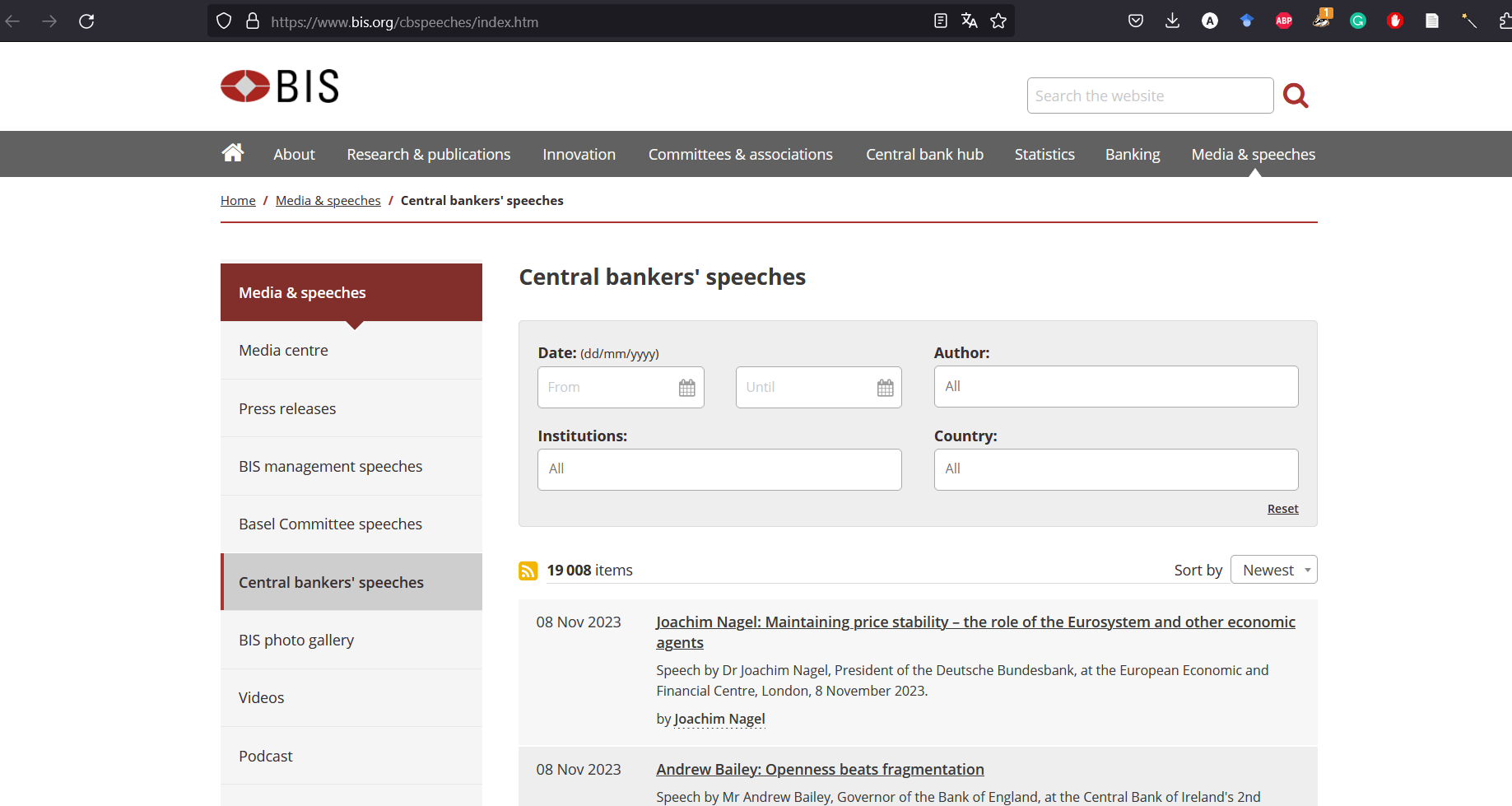
Figure 1: La liste des discours de la BRI
Ce que nous voulons, c’est :
- extraire les métadonnées de ces discours : la date du discours, le titre, la description et l’orateur.
- d’accéder au texte complet du discours, qui est stocké dans un PDF sur le site web de la BIS
- d’extraire le texte de ce PDF
- s’assurer que le texte est lisible, ce qui sera le cas si le PDF est “cherchable” (c’est-à-dire si les caractères sont reconnus).
C’est tout cela que nous allons apprendre à faire dans ce tutoriel.
Chargement des packages et démarrage du navigateur automatisé
Nous commençons par charger les packages nécessaires. RSelenium (Harrison 2022) et polite sont les paquets centraux ici. J’aime bien le package here pour manipuler les chemins avec R mais il n’est pas essentiel ici. glue est utilisé pour créer des chaînes de caractères plus facilement, en y intégrant des expressions R. pdftools sera utilisé pour extraire le texte des PDF des discours et tesseract pour lancer la reconnaissance optique de caractères (OCR) sur les PDFs qui ne disposent pas d’un bon OCR.
# pacman is a useful package to install missing packages and load them
if(! "pacman" %in% installed.packages()){
install.packages("pacman", dependencies = TRUE)
}
pacman::p_load(tidyverse,
RSelenium,
polite,
glue,
here,
pdftools,
tesseract)
bis_data_path <- here(path.expand("~"), "data", "central_bank_database", "BIS") # Where data will go on my computer
Aller sur le site web de la BRI et lancer le bot
Nous utilisons polite pour nous “incliner” devant le site web de la BRI. Cela nous permet d’examiner les autorisations pour le scraping.
bis_website_path <- "https://www.bis.org/"
session <- bow(bis_website_path)
session
## <polite session> https://www.bis.org/
## User-agent: polite R package
## robots.txt: 15 rules are defined for 2 bots
## Crawl delay: 5 sec
## The path is scrapable for this user-agent
En examinant le fichier robots.txt, nous pouvons voir plus en détail quels chemins du site web sont moissonnables ou non.
cat(session$robotstxt$text)
## #Format is:
## # User-agent: <name of spider>
## # Disallow: <nothing> | <path>
## #-------------------------------------------
##
## User-Agent: *
## Disallow: /dcms
## Disallow: /metrics/
## Disallow: /search/
## Disallow: /staff.htm
## Disallow: /embargo/
## Disallow: /app/
## Disallow: /goto.htm
## Disallow: /login
## #Disallow: /cbhub
## Disallow: /cbhub/goto.htm
## Disallow: /doclist/
## # Committee comment letters
## Disallow: /publ/bcbs*/
## Disallow: /bcbs/ca/
## Disallow: /bcbs/commentletters/
## Disallow: /*/publ/comments/
## # Hide the Basel Framework standards, only chapters should be indexed.
## Disallow: /basel_framework/standard/
##
## Sitemap: https://www.bis.org/sitemap.xml
La liste des discours se trouve à “https://www.bis.org/cbspeeches/index.htm”. Ce chemin ne fait pas partie de la liste “disallow”, ce qui signifie que nous pouvons récupérer cette partie du site web.
Afin de faciliter le scraping, nous afficherons le nombre maximal d’éléments par page, qui est ici de 25. Nous ne voulons pas moissonner toute la liste des discours, nous allons donc fixer une date de départ : le 9 octobre 2023. En naviguant vers la deuxième page de la liste obtenue, vous pouvez maintenant avoir une idée de ce à quoi ressemble l’URL.
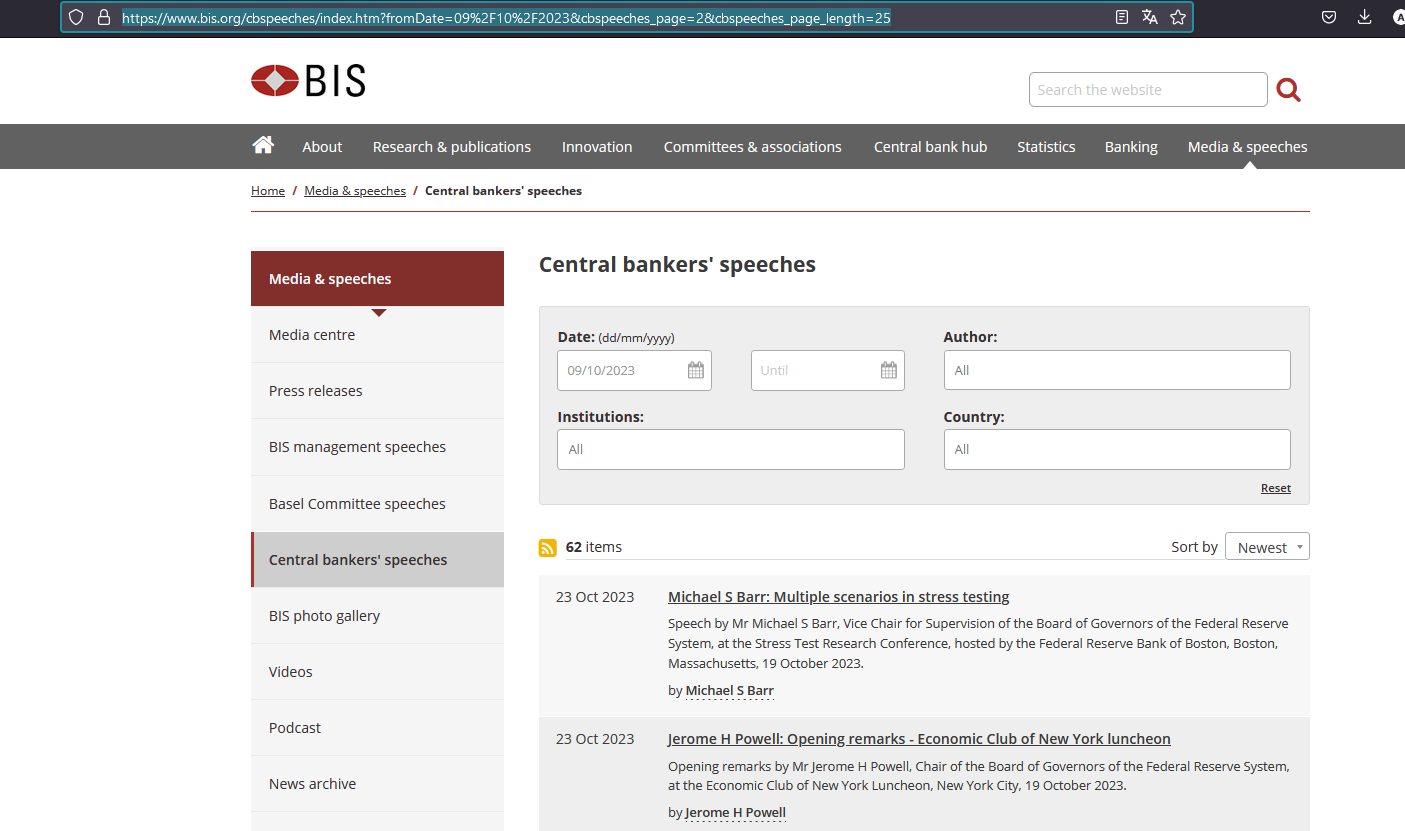
Figure 2: Discours filtrés sur le site de la BRI
Ainsi, vous pouvez préparer une URL pré-formatée, dans laquelle vous pouvez modifier les paramètres.
scraping_path <- expr(glue("{bis_website_path}cbspeeches/index.htm?fromDate={day}%2F{month}%2F{year}&cbspeeches_page={page}&cbspeeches_page_length=25"))
Ici, j’aurais pu utiliser un code plus simple en utilisant la fonction paste0() par exemple, plutôt que d’utiliser expr(). Mais je veux pouvoir changer les paramètres plus tard, notamment pour le numéro de page. Pour l’instant, le chemin ressemble à ceci :
scraping_path
## glue("{bis_website_path}cbspeeches/index.htm?fromDate={day}%2F{month}%2F{year}&cbspeeches_page={page}&cbspeeches_page_length=25")
Mais je peux alors entrer les paramètres que je souhaite pour la date (ici, le 9 octobre 2023).
day <- "09"
month <- "10"
year <- 2023
Et je peux évaluer l’expression avec ces paramètres, en entrant également une certaine page. Cela sera utile plus tard dans une boucle pour naviguer d’une page à l’autre.
eval(scraping_path, envir = list(page = 3))
## https://www.bis.org/cbspeeches/index.htm?fromDate=09%2F10%2F2023&cbspeeches_page=3&cbspeeches_page_length=25
Vous pouvez vérifier que cette URL vous conduit à la troisième page de la liste des discours commençant le 9 octobre 2023 (avec 25 résultats par page).
Une fois que vous avez la structure de l’URL, cela signifie que vous pouvez modifier les paramètres à votre guise pour créer la liste de discours que vous souhaitez. Bien sûr, vous pouvez aller sur le site de la BRI et filtrer par la date de fin ou par les “institutions” ou le “pays” pour voir à quoi ressemblerait l’URL.
Maintenant, nous pouvons commencer la partie amusante. Lançons notre navigateur automatisé avec RSelenium :
# Launch Selenium to go on the website of bis
driver <- rsDriver(browser = "firefox", # can also be "chrome"
chromever = NULL,
port = 4444L)
remote_driver <- driver[["client"]]
Figure 3: Automatizing your web browser
Extraction des données page par page
Ce que nous voulons faire, c’est extraire les données relatives à chaque discours (la date, le titre, la description, l’orateur et l’URL correspondante) page par page. Nous pouvons faire cela avec une boucle for. Mais nous devons d’abord connaître le nombre de pages. Vous pouvez normalement le voir en bas à droite de la page web.
Il existe différentes façons d’extraire cette information. Ici, nous utiliserons le “sélecteur CSS”. L’utilisation du sélecteur CSS présente deux avantages :
- son contenu est généralement plus simple que celui d’un XPATH
- Il peut être facilement récupéré grâce à un module complémentaire de Firefox (qui existe également pour Chrome) : ScrapeMate
Une fois l’add-on installé, vous pouvez aller sur l’URL sur laquelle nous travaillons et trouver le “CSS selector” pour le nombre de pages :
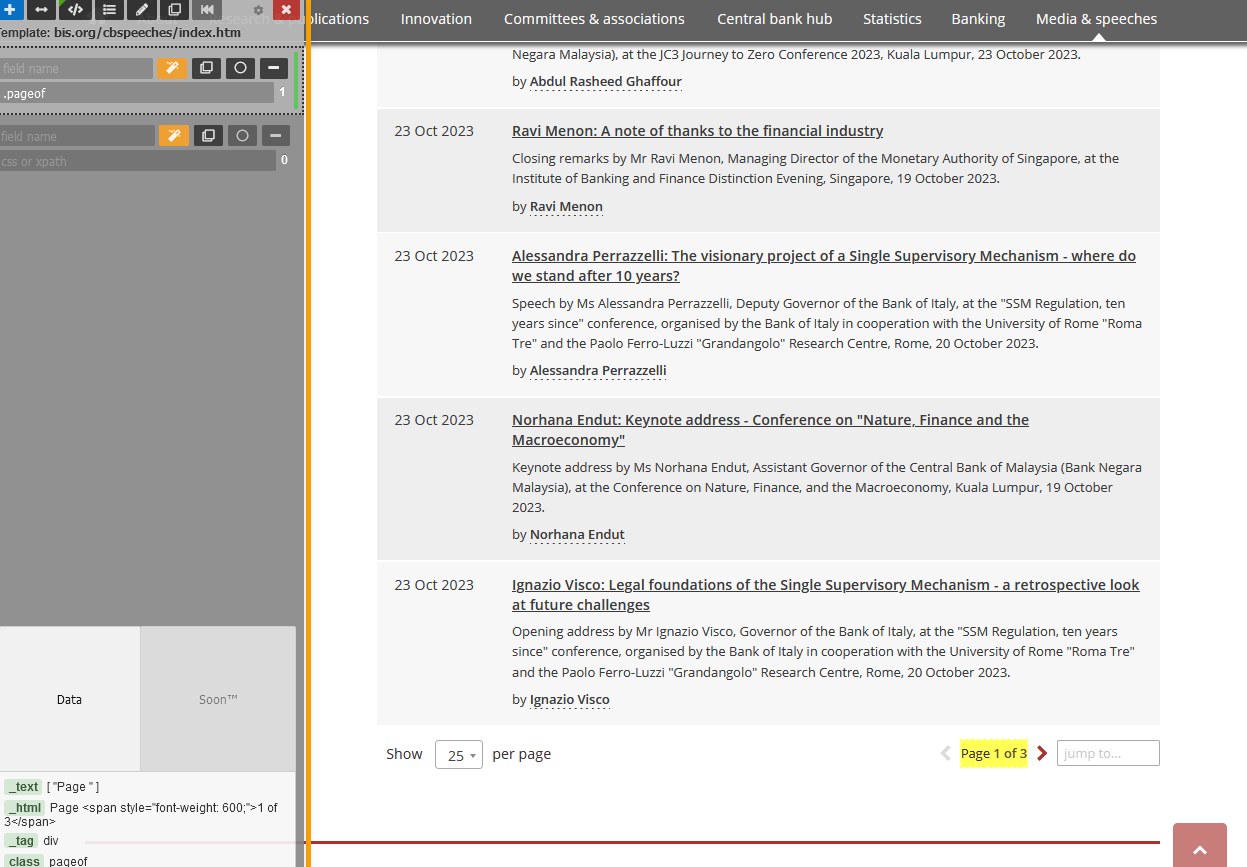
Figure 4: Using scrapemate Firefox addon
Vous pouvez utiliser ce sélecteur CSS pour extraire le texte grâce à RSelenium et après un court nettoyage, vous obtenez le nombre total de pages :
remote_driver$navigate(eval(scraping_path, envir = list(page = 1)))
Sys.sleep(2) # Just to have time to load the page
nb_pages <- remote_driver$findElement("css selector", ".pageof")$getElementText() %>% # We just set i for searching the total number of pages
pluck(1) %>%
str_remove_all("Page 1 of ") %>%
as.integer()
nb_pages
## [1] 6
Ok. Maintenant, nous pouvons exécuter la boucle pour récupérer toutes les données des 6 pages. Ici, nous nous conformerons au délai fixé par le paquet polite : nous attendrons 5 secondes pour chaque page, afin de ne pas surcharger le site web avec trop de requêtes. Comme nous avons besoin que la page web se charge correctement pour récupérer les données, c’est aussi un moyen de prendre le temps de charger la page pour éviter de manquer des données si votre connexion internet est trop lente.
Il suffit d’utiliser scrapemate pour trouver le sélecteur CSS approprié pour chaque information et extraire le texte correspondant. Vous pouvez également voir qu’en cliquant sur le titre du discours, vous naviguez vers la page web dédiée au discours correspondant. Cela signifie qu’au titre est associé un lien URL, un “href” en langage html. Il faut donc extraire l’attribut “href” associé au titre grâce à RSelenium.
metadata <- vector(mode = "list", length = nb_pages)
for(page in 1:nb_pages){
remote_driver$navigate(eval(scraping_path))
nod <- nod(session, eval(scraping_path)) # introducing to the new page
Sys.sleep(session$delay) # using the delay time set by polite
metadata[[page]] <- tibble(date = remote_driver$findElements("css selector", ".item_date") %>%
map_chr(., ~.$getElementText()[[1]]),
info = remote_driver$findElements("css selector", ".item_date+ td") %>%
map_chr(., ~.$getElementText()[[1]]),
url = remote_driver$findElements("css selector", ".dark") %>%
map_chr(., ~.$getElementAttribute("href")[[1]]))
}
metadata <- bind_rows(metadata) %>%
separate(info, c("title", "description", "speaker"), "\n")
head(metadata)
## # A tibble: 6 × 5
## date title description speaker url
## <chr> <chr> <chr> <chr> <chr>
## 1 27 Nov 2023 "Ahmet Ismaili: Welcoming remarks - Wor… "Welcoming… by Ahm… http…
## 2 27 Nov 2023 "Ahmet Ismaili: Creating values – a gat… "Introduct… by Ahm… http…
## 3 22 Nov 2023 "Christine Lagarde: Monetary policy in … "Speech by… by Chr… http…
## 4 22 Nov 2023 "Sabine Mauderer: Exposing and acting o… "Speech by… by Sab… http…
## 5 21 Nov 2023 "Jon Cunliffe: Money and payments - a \… "Speech by… by Jon… http…
## 6 21 Nov 2023 "Shaktikanta Das: Emerging India - a la… "Keynote s… by Sha… http…
La fonction findElements() de RSelenium trouve tous les éléments correspondants (ici 25) et les stocke dans une liste. La fonction map_chr() permet d’obtenir le texte de chaque élément un par un et stocke le résultat dans un vecteur.
Si nous voulons être sûrs d’avoir récupéré les données de tous les discours, nous pouvons comparer la longueur de notre tableau de données avec le nombre d’éléments indiqué juste au-dessus du premier discours.
# We just check that we have the correct number of speeches
nb_items <- remote_driver$findElement("css selector", ".listitems")$getElementText() %>% # We just set i for searching the total number of pages
pluck(1) %>%
str_remove_all("[\\sitems]") %>%
as.integer()
if(nb_items == nrow(metadata)){
cat("You have extracted the metadata of all speeches")
} else{
cat("There is a problem. You have probably missed some speeches.")
}
## You have extracted the metadata of all speeches
Télécharger les PDFs
Nous disposons à présent des métadonnées des discours. Mais ce qui nous intéresse à la fin, c’est de savoir de quoi parlent les discours. La plupart des discours sont stockés dans un fichier PDF. Pour récupérer ces PDF, il suffit d’utiliser l’URL du discours, et de remplacer la fin de l’URL “.htm” par “.pdf”. À partir de la liste des métadonnées, on peut obtenir la liste complète des PDF que l’on souhaite télécharger.
pdf_to_download <- metadata %>%
mutate(pdf_name = str_extract(url, "r\\d{6}[a-z]"),
pdf_name = str_c(pdf_name, ".pdf")) %>%
pull(pdf_name)
pdf_to_download
## [1] "r231127c.pdf" "r231127d.pdf" "r231122b.pdf" "r231122a.pdf" "r231121a.pdf"
## [6] "r231115e.pdf" "r231121i.pdf" "r231121h.pdf" "r231121g.pdf" "r231121f.pdf"
## [11] "r231121e.pdf" "r231121d.pdf" "r231121c.pdf" "r231121b.pdf" "r231120j.pdf"
## [16] "r231120h.pdf" "r231120i.pdf" "r231114a.pdf" "r231114b.pdf" "r231115r.pdf"
## [21] "r231115s.pdf" "r231114c.pdf" "r231115t.pdf" "r231115u.pdf" "r231120g.pdf"
## [26] "r231120f.pdf" "r231120e.pdf" "r231120d.pdf" "r231120c.pdf" "r231120b.pdf"
## [31] "r231120a.pdf" "r231113s.pdf" "r231115q.pdf" "r231115o.pdf" "r231115n.pdf"
## [36] "r231115m.pdf" "r231115j.pdf" "r231115i.pdf" "r231115f.pdf" "r231115h.pdf"
## [41] "r231115g.pdf" "r231114d.pdf" "r231115d.pdf" "r231115p.pdf" "r231113n.pdf"
## [46] "r231115a.pdf" "r231113m.pdf" "r231115c.pdf" "r231114e.pdf" "r231114f.pdf"
## [51] "r231113t.pdf" "r231113o.pdf" "r231113q.pdf" "r231113x.pdf" "r231113w.pdf"
## [56] "r231113v.pdf" "r231113u.pdf" "r231113p.pdf" "r231113r.pdf" "r231113k.pdf"
## [61] "r231113j.pdf" "r231113i.pdf" "r231113h.pdf" "r231113g.pdf" "r231113f.pdf"
## [66] "r231113e.pdf" "r231113d.pdf" "r231113c.pdf" "r231113b.pdf" "r231113l.pdf"
## [71] "r231113a.pdf" "r231110a.pdf" "r231108c.pdf" "r231108b.pdf" "r231108a.pdf"
## [76] "r231107c.pdf" "r231107b.pdf" "r231107a.pdf" "r231102a.pdf" "r231027b.pdf"
## [81] "r231115l.pdf" "r231026l.pdf" "r231026j.pdf" "r231026q.pdf" "r231026g.pdf"
## [86] "r231026f.pdf" "r231026e.pdf" "r231026m.pdf" "r231026d.pdf" "r231026c.pdf"
## [91] "r231026b.pdf" "r231026a.pdf" "r231023h.pdf" "r231023g.pdf" "r231023e.pdf"
## [96] "r231023c.pdf" "r231023b.pdf" "r231023a.pdf" "r231020f.pdf" "r231020e.pdf"
## [101] "r231020d.pdf" "r231020c.pdf" "r231020b.pdf" "r231020a.pdf" "r231019g.pdf"
## [106] "r231019e.pdf" "r231019d.pdf" "r231019c.pdf" "r231019b.pdf" "r231019a.pdf"
## [111] "r231018f.pdf" "r231018e.pdf" "r231018d.pdf" "r231018c.pdf" "r231018b.pdf"
## [116] "r231018a.pdf" "r231017e.pdf" "r231017d.pdf" "r231017c.pdf" "r231017b.pdf"
## [121] "r231012a.pdf" "r231017a.pdf" "r231011d.pdf" "r231012b.pdf" "r231011g.pdf"
## [126] "r231011f.pdf" "r231011e.pdf" "r231011a.pdf" "r231011b.pdf" "r231010h.pdf"
## [131] "r231010g.pdf" "r231010f.pdf" "r231010e.pdf" "r231010d.pdf" "r231010c.pdf"
## [136] "r231010b.pdf" "r231010a.pdf" "r231115v.pdf"
Nous construisons une fonction pour télécharger ces PDF en utilisant polite. Cela évitera notamment de surcharger le site.
polite_download <- function(domain, url, ...){
bow(domain) %>%
nod(glue(url)) %>%
rip(...)
}
Il est possible que certains PDF soient manquants (ce n’est pas le cas ici, mais cela arrive avec l’ensemble des discours de la BRI). Le problème est que si un PDF est manquant, vous obtiendrez une erreur et le processus de téléchargement du PDF sera interrompu. Vous devez donc utiliser la fonction tryCatch() pour prendre en compte cette erreur mais continuer le processus de téléchargement.
tryCatch(
{
walk(pdf_to_download, ~polite_download(domain = bis_website_path,
url = glue("review/{.}"),
path = here(bis_data_path, "pdf"),))
},
error = function(e) {
print(glue("No pdf exist"))
}
)
Ici, le pdf a été stocké dans un dépôt spécifique sur mon ordinateur, indiqué par le paramètre path.
Extraire le texte des discours
Maintenant que nous avons collecté les PDF, nous voulons extraire le texte contenu dans ces PDF. Nous utiliserons pour cela le paquet pdftools. Voici une fonction qui prend la liste des PDFs extraits des métadonnées, extrait le texte, et le stocke dans un tableau avec le nom du fichier et la page correspondante du texte (en effet, pdf_text() extrait le texte page par page). Ici, nous enregistrons l’erreur au cas où nous n’aurions pas trouvé le PDF : nous ne voulons pas que l’extraction du texte s’arrête, mais nous voulons nous souvenir qu’un PDF est manquant.
extracting_text <- function(file, path) {
tryCatch(
{
message(glue("Extracting text from {file}"))
text_data <- pdf_text(here(path, file)) %>%
as_tibble() %>%
mutate(page = 1:n(),
file = file) %>%
rename(text = value)
},
error = function(e) {
print(glue("No pdf exist"))
text_data <- tibble(text = NA,
page = 1,
file = file)
}
)
}
Nous pouvons exécuter la fonction pour chaque discours que nous avons dans notre ensemble de données.
text_data <- map(pdf_to_download, ~extracting_text(., here(bis_data_path, "pdf"))) %>%
bind_rows()
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
## No pdf exist
head(text_data)
## # A tibble: 6 × 3
## text page file
## <chr> <dbl> <chr>
## 1 "Ahmet Ismaili: Welcoming remarks - World Savings Day\nWelcoming … 1 r231…
## 2 "Young people should set clear financial goals for themselves and… 2 r231…
## 3 "Ahmet Ismaili: Creating values – a gateway for the future\nIntro… 1 r231…
## 4 "Therefore, in CBK's supervisory role, the external auditor profe… 2 r231…
## 5 "3/3 BIS - Central bankers' speeches\n" 3 r231…
## 6 "Christine Lagarde: Monetary policy in the euro area - attentive … 1 r231…
Gestion des problèmes d’OCR
Il arrive que les PDF présentent des problèmes d’OCR. Les PDF ne sont pas “recherchables” et le texte ne peut donc pas être extrait correctement (ou plutôt, il est illisible). Cela se produit également avec des discours récents. Nous devons donc trouver les PDFs susceptibles de rencontrer de tels problèmes. Nous comptons le nombre de mots dans chaque page et récupérons les PDFs pour lesquels le nombre de mots est faible dans chaque page.
pdf_without_ocr <- text_data %>%
mutate(test_ocr = str_count(text, "[a-z]+")) %>% # Count the number of words
mutate(non_ocr_document = all(test_ocr < 250), .by = file) %>%
filter(non_ocr_document == TRUE) %>%
distinct(file) %>%
pull()
pdf_without_ocr
## [1] "r231122a.pdf" "r231121h.pdf" "r231121g.pdf" "r231121d.pdf" "r231110a.pdf"
## [6] "r231026f.pdf" "r231026c.pdf" "r231023h.pdf" "r231023g.pdf" "r231017d.pdf"
## [11] "r231017b.pdf" "r231011g.pdf" "r231010g.pdf" "r231010e.pdf" "r231010d.pdf"
## [16] "r231010c.pdf" "r231010b.pdf"
Le fait de fixer le seuil à 250 mots est une simple règle empirique dans ce cas précis : cela permet de n’avoir que des vrais positifs, mais n’empêche pas d’avoir des faux négatifs (des documents avec un problème d’OCR que nous avons raté). Il devrait être possible de trouver une meilleure méthode pour évaluer quels PDFs n’ont pas d’OCR.
Voici un exemple de PDF problématique :
text_data %>%
filter(file %in% pdf_without_ocr[1])
## # A tibble: 6 × 3
## text page file
## <chr> <dbl> <chr>
## 1 "012345637839 \u0011 3 7839843 \u0011\u000e433\u000f\u00103783984… 1 r231…
## 2 "01ÿ34567567ÿ85996ÿ45 ÿ\u000e\u000fÿ56\u000fÿ\u000f8ÿ\u00106ÿ\u00… 2 r231…
## 3 "0123456ÿ89252 49ÿ2 8ÿ\u000e8ÿ\u000f2ÿ94\u0010\u000f8ÿ9\u0011\u00… 3 r231…
## 4 "01ÿ3456ÿ17389ÿ83ÿ 8ÿ454543ÿ348ÿ57188\u000e51 ÿ\u000f7\u000e\u001… 4 r231…
## 5 "0123ÿ56ÿ718ÿ319\n ÿ\u000e\u000f9\u00103\u00112\u0012ÿ\u0013… 5 r231…
## 6 "0ÿ2345678934\n \u000e\u000fÿ\u0011 ÿ\u0012\u000e\u0011\u0013\… 6 r231…
Il semble correct lorsqu’on le regarde, mais en allant sur la page web on voit qu’il y a des problèmes de sélection dans le texte et que l’OCR n’est donc pas adéquate.

Figure 5: PDF sans OCR adéquate
Nous allons maintenant utiliser le paquet tesseract, qui exécute l’OCR. Il convertit d’abord chaque page du PDF en une image (PNG), puis procède à l’OCR et extrait le texte.
new_text_ocr <- vector(mode = "list", length = length(pdf_without_ocr))
for(i in 1:length(pdf_without_ocr)){
text <- tesseract::ocr(here(bis_data_path, "pdf", pdf_without_ocr[i]), engine = tesseract::tesseract("eng"))
text <- tibble(text) %>%
mutate(text = str_remove(text, ".+(=?\\\n)"),
page = 1:n(),
file = str_remove(pdf_without_ocr[i], "\\.pdf"))
new_text_ocr[[i]] <- text
}
new_text_ocr <- bind_rows(new_text_ocr)
## Converting page 1 to r231122a_1.png... done!
## Converting page 2 to r231122a_2.png... done!
## Converting page 3 to r231122a_3.png... done!
## Converting page 4 to r231122a_4.png... done!
## Converting page 5 to r231122a_5.png... done!
## Converting page 6 to r231122a_6.png... done!
Vous pouvez constater que le texte est maintenant lisible :
new_text_ocr
## # A tibble: 6 × 3
## text page file
## <chr> <int> <chr>
## 1 "Exposing and acting on risks in a fast-changing\nworld\nEIOPA An… 1 r231…
## 2 "that might be emerging, we might also be able to open up new hor… 2 r231…
## 3 "industry. Recent earnings releases by large insurers show that h… 3 r231…
## 4 "Financial System (\n\nNGFS (Central Banks and Supervisors Networ… 4 r231…
## 5 "\nNGFS (Central Banks and Supervisors Network for Greening the F… 5 r231…
## 6 "\nLadies and gentlemen,\n\nTo come back to the animal-based meta… 6 r231…
Il ne vous reste plus qu’à intégrer le texte reconnu au reste des données. Une dernière petite étape consiste à supprimer tous les PNGs que vous avez créés en utilisant tesseract.
# We remove all the .png we have created
png_to_remove <- list.files()[str_which(list.files(), "_\\d+\\.png")]
file.remove(png_to_remove)
Si vous souhaitez récupérer les discours de la BRI sur une base régulière sans récupérer à nouveau ce que vous avez déjà collecté, vous pouvez jeter un oeil à ce script ici, qui fait partie d’un projet de collecte de documents des banques centrales. Vous y trouverez également des fonctions pour nettoyer les données de la BRI.
Bibliography
Harrison, John. 2022. RSelenium: R Bindings for ’Selenium WebDriver’. https://CRAN.R-project.org/package=RSelenium.
Perepolkin, Dmytro. 2023. Polite: Be Nice on the Web. https://CRAN.R-project.org/package=polite.
Wickham, Hadley. 2022. Rvest: Easily Harvest (Scrape) Web Pages. https://CRAN.R-project.org/package=rvest.
Wickham, Hadley, Mine Çetinkaya-Rundel, and Garrett Grolemund. 2023. R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. 2nd edition. Sebastopol, CA: O’Reilly Media.
Je ne suis pas un spécialiste des structures html, mais je n’ai pas réussi à extraire les données en utilisant uniquement rvest. J’ai donc utilisé RSelenium, et RSelenium uniquement, même si la plupart du temps on combine les deux packages ↩︎
Aurélien Goutsmedt
Chercheur Postdoctoral et Chargé de Cours
Je travaille sur l’histoire de l’économie et l’expertise économique.