Scraping Documents from the Bank of England Website
Scraping Tutorials 3
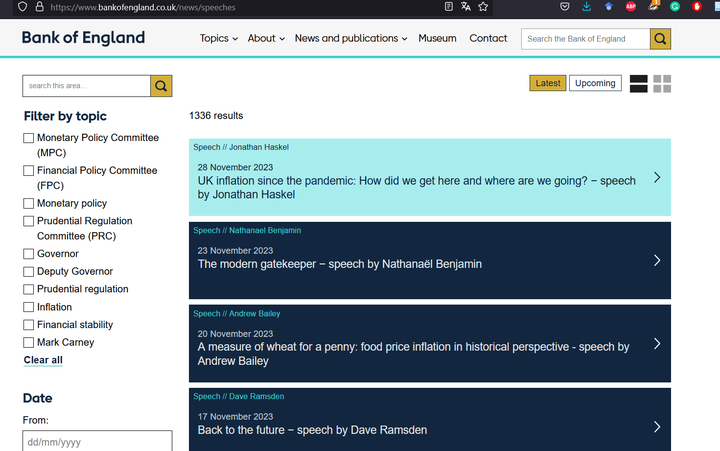
Table of Contents
In the first tutorial on web scraping, I explained how to scrape the Bank of International Settlements database of speeches. The second tutorial focused on the working papers of the European Central Bank website. In this third post, I will show a method to scrape documents from the Bank of England’s website.
In the first two posts, we had a list of documents on a webpage with different information (or “metadata”) that we wanted to scrape. For the BIS, we needed to understand the structure of the URL, to use it to change the page and scrape the metadata for all the speeches we were interested in. For the ECB, we rather needed to scroll down and click on menus to open additional details. Here, we will use a radically different approach, which involves retrieving the structure of the website, the “sitemap”, to see where we can find the metadata for the documents.1
Unlike the first two posts, we won’t need RSelenium (Harrison 2022) here. We will only use rvest (Wickham 2022) and polite (Perepolkin 2023). Indeed, the chosen method doesn’t involve interacting with a web browser.
# pacman is a useful package to install missing packages and load them
if(! "pacman" %in% installed.packages()){
install.packages("pacman", dependencies = TRUE)
}
pacman::p_load(tidyverse,
rvest,
polite)
A look at the BoE Website
Let’s have a look, for instance, at the speeches of the BoE at https://www.bankofengland.co.uk/news/speeches.

Figure 1: BoE Speeches
We have a list of speeches that is relatively similar to what we had for the BIS, with a list of pages that you can change to the bottom of the webpage. However, the URL stays the same when you move to another page. I have not found any way to manipulate the URL in order to move from a page to another. But you could easily use RSelenium to click on the button to go to the next page.
Nonetheless, we can collect more information by clicking on each speech, as each speech has a dedicated webpage like this:

Figure 2: A Speech Webpage
This means that for each speech of the BoE’s policymakers, an URL exists, and thus we should be able to find this URL from the “sitemap”.2
Exploring the Sitemap
As explained in the first tutorial, it is important to tell the website who we are and to check the scraping rules on that site by reading the robot.txt.
root_url_BoE <- "https://www.bankofengland.co.uk"
user_agent <- "polite R package - used for https://github.com/agoutsmedt/central_bank_database (aurelien.goutsmedt[at]uclouvain.be)"
session <- bow(root_url_BoE,
user_agent = user_agent)
session$robotstxt$text
## [robots.txt]
## --------------------------------------
##
## User-agent: *
## Disallow: /boeapps/database/ShowChart.asp
## Disallow: /boeapps/database/_iadb-FromShowColumns.asp
## Disallow: /boeapps/iadb
## Disallow: /boeapps/titan
## Disallow: /error
## Disallow: /forms
## Disallow: /mfsd
## Disallow: /search
## Disallow: /test-folder
## Disallow: /-/media/boe/files/markets/benchmarks/sonia-statement-of-compliance-with-the-iosco-principles-for-financial-benchmarks.pdf
##
## Sitemap: https://www.bankofengland.co.uk/_api/sitemap/getsitemap
## Host: www.bankofengland.co.uk
The robot.txt also indicates the URL of the sitemap:
sitemap <- session$robotstxt$sitemap$value
sitemap
## [1] "https://www.bankofengland.co.uk/_api/sitemap/getsitemap"
This webpage gathers a (very long) list of all the existing URLs of the website. You can try to have a look at it on your browser, but it takes a very long time to load. The easiest is to read it directly here using rvest.
xml_sitemap <- rvest::read_html(sitemap)
xml_sitemap %>% html_element(xpath = "body")
## {html_node}
## <body>
## [1] <urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"><url><loc>htt ...
We can see that it is the “loc” argument that interests us.
data_frame_sitemap <- tibble(hyperlink= xml_sitemap %>%
rvest::html_elements(xpath = ".//loc") %>%
rvest::html_text()) %>%
filter(hyperlink != root_url_BoE) # we exclude the base url that we don't need anymore
data_frame_sitemap
## # A tibble: 13,140 × 1
## hyperlink
## <chr>
## 1 https://www.bankofengland.co.uk/about
## 2 https://www.bankofengland.co.uk/about/corporate-responsibility
## 3 https://www.bankofengland.co.uk/about/corporate-responsibility/carbon-target…
## 4 https://www.bankofengland.co.uk/about/corporate-responsibility/charities-of-…
## 5 https://www.bankofengland.co.uk/about/get-involved
## 6 https://www.bankofengland.co.uk/about/get-involved/citizens-panels
## 7 https://www.bankofengland.co.uk/about/get-involved/citizens-panels/cara-pete…
## 8 https://www.bankofengland.co.uk/about/get-involved/citizens-panels/emma-young
## 9 https://www.bankofengland.co.uk/about/get-involved/citizens-panels/insights-…
## 10 https://www.bankofengland.co.uk/about/get-involved/citizens-panels/nick-chen…
## # ℹ 13,130 more rows
We now have a list of 13140 URLs. What we need to do now is to understand what these URLs are about. We can find this by looking at what follows the base URLs:
data_frame_sitemap <- data_frame_sitemap %>%
mutate(category = str_remove(hyperlink, "https://www.bankofengland.co.uk/") %>%
str_remove("/.*"))
unique(data_frame_sitemap$category)
## [1] "about" "accessibility"
## [3] "agents-summary" "alternative-liquidity-facility"
## [5] "annual-report" "archive"
## [7] "article" "asset-purchase-facility"
## [9] "bank-liabilities-survey" "bank-overground"
## [11] "banking-services" "banknotes"
## [13] "careers" "ccbs"
## [15] "climate-change" "contact"
## [17] "coronavirus" "cost-of-living"
## [19] "credit-conditions-review" "credit-conditions-survey"
## [21] "decision-maker-panel" "education"
## [23] "eu-withdrawal" "events"
## [25] "explainers" "external-mpc-discussion-paper"
## [27] "faq" "financial-policy-summary-and-record"
## [29] "financial-stability" "financial-stability-in-focus"
## [31] "financial-stability-paper" "financial-stability-report"
## [33] "freedom-of-information" "gold"
## [35] "independent-evaluation-office" "inflation-attitudes-survey"
## [37] "inflation-report" "legal"
## [39] "letter" "markets"
## [41] "minutes" "monetary-policy"
## [43] "monetary-policy-report" "monetary-policy-summary-and-minutes"
## [45] "museum" "news"
## [47] "paper" "payment-and-settlement"
## [49] "prudential-regulation" "quarterly-bulletin"
## [51] "record" "report"
## [53] "research" "rss"
## [55] "sitemap" "speech"
## [57] "statement" "statistics"
## [59] "sterling-monetary-framework" "sterling-money-market-survey"
## [61] "stress-testing" "subscribe-to-emails"
## [63] "systemic-risk-survey" "the-digital-pound"
## [65] "vulnerability-disclosure-policy" "weekly-report"
## [67] "whistleblowing" "working-paper"
We can now filter the URLs depending on what we want to scrape. For this time, let’s forget the speeches and say that we are interested in the “minutes”:
minutes_urls <- data_frame_sitemap %>%
filter(category == "minutes")
minutes_urls
## # A tibble: 669 × 2
## hyperlink category
## <chr> <chr>
## 1 https://www.bankofengland.co.uk/minutes/1997/monetary-policy-commit… minutes
## 2 https://www.bankofengland.co.uk/minutes/1997/monetary-policy-commit… minutes
## 3 https://www.bankofengland.co.uk/minutes/1997/monetary-policy-commit… minutes
## 4 https://www.bankofengland.co.uk/minutes/1997/monetary-policy-commit… minutes
## 5 https://www.bankofengland.co.uk/minutes/1997/monetary-policy-commit… minutes
## 6 https://www.bankofengland.co.uk/minutes/1997/monetary-policy-commit… minutes
## 7 https://www.bankofengland.co.uk/minutes/1997/monetary-policy-commit… minutes
## 8 https://www.bankofengland.co.uk/minutes/1998/monetary-policy-commit… minutes
## 9 https://www.bankofengland.co.uk/minutes/1998/monetary-policy-commit… minutes
## 10 https://www.bankofengland.co.uk/minutes/1998/monetary-policy-commit… minutes
## # ℹ 659 more rows
Scraping Minutes Metadata
Thanks to the URLs of the minutes, we have the year of the minutes. Let’s focus on the minutes of 2023.
minutes_urls <- minutes_urls %>%
mutate(dates = str_extract(hyperlink, "(?<=/)\\d{4}(?=/)") %>% as.integer()) %>%
filter(dates == 2023)
Here is the first URL in our data:

Figure 3: A Minutes Webpage
Using rvest, we first extract the html code of the first webpage. You can see that the text of the minutes can be extracted directly from this webpage. We want to scrape the title of the document, its date, its summary, and the text content.
# first, we read the html
page <- minutes_urls %>%
slice(1) %>%
pull(hyperlink) %>%
read_html
# second, we extract the different information
extracted_title <- page %>%
html_nodes("h1") %>%
html_text()
extracted_date <- page %>%
html_nodes(".published-date") %>%
html_text(trim = TRUE) %>%
str_extract("\\d+ [A-z]+ \\d+$") %>%
dmy()
# As the abstract and the text may gather several paragraphs, the object could be a vector of several strings. We thus save these strings as a list format (because we want one line per URL/document)
abstract <- page %>%
html_nodes(".hero") %>%
html_text(trim= TRUE) %>%
list()
text <- page %>%
# We extract the titles and the text together
html_nodes('.page-section .content-block h2 , .page-section .content-block h3, .page-section .content-block .page-content p') %>%
html_text() %>%
list()
metadata <- tibble(title = extracted_title,
date = extracted_date,
abstract = abstract,
text = text)
metadata
## # A tibble: 1 × 4
## title date abstract text
## <chr> <date> <list> <lis>
## 1 Minutes of the Meeting of the Court of Directors he… 2023-06-08 <chr> <chr>
We can have a look at the first lines of the text extracted:
metadata %>%
pull(text) %>%
unlist() %>%
.[1:30] %>%
str_c(collapse = "\n") %>%
cat()
## Present:
## David Roberts, Chair
## Andrew Bailey, Governor
## Ben Broadbent, Policy
## Sir Jon Cunliffe, Deputy Governor – Financial Stability
## Sir Dave Ramsden, Deputy Governor – Markets & Banking
## Sam Woods, Deputy Governor – Prudential Regulation
## Sabine Chalmers
## Lord Jitesh Gadhia
## Anne Glover
## Sir Ron Kalifa
## Diana Noble
## Frances O’Grady
## Tom Shropshire
## In attendance:
## Ben Stimson, Chief Operating Officer
## Secretary:
## Sebastian Walsh
## 1. Conflicts, Minutes and Matters Arising
## There were no conflicts declared in relation to the present agenda.
## The minutes of the meeting held on 8 February 2023 were approved.
## The Chair noted that a number of steps had been introduced to support the effectiveness of Court meetings.
## The Chair welcomed Ruth Smith to the meeting and noted that Ruth had been appointed as interim Secretary of the Bank.
## 2. Governor’s Update
## The Governor updated Court on recent developments in the banking system.
## The Governor reflected that recent weeks had seen two banks with UK operations fail and parts of the financial sector come under stress. Silicon Valley Bank (SVB) and its UK subsidiary failed on 10 March due to a deposit run following significant losses in the US parent. Court observed the speed of the run on SVB. Court noted the factors underlying this, including the extent to which social media now drives bank runs.
## The PRA’s approach to the UK operations of SVB ensured a greater degree of financial resilience, particularly the subsidiarisation policy. Over the weekend that SVB UK failed, the Bank conducted a successful resolution transaction – demonstrating the effective operation of the UK’s resolution regime. SVB UK’s capital instruments were written down, and the firm was sold to HSBC. The Bank’s actions protected both depositors and public funds.
## The Governor set out that the resolution plan for Credit Suisse was well-rehearsed by the UK, US and Swiss authorities. However, the Swiss authorities had not used the resolution plan. Instead, the Swiss conducted a going-concern sale underpinned by some public support, which in turn effected a full write-down of subordinated debt instruments, while equity was only partially written down. There had been some brief fallout in AT1 markets following this action, but swift communications from the UK and EU authorities on their approach to the creditor hierarchy in resolution had stemmed this.
## Though SVB and Credit Suisse had failed for different reasons, the events had taken place in close proximity to each other. As a result of this, investors perceived that the outlook for the global banking sector was uncertain. The Governor noted that more broadly the backdrop for these events was an uncertain outlook for global economic activity. The Bank was monitoring the financial system closely, particularly the impact of recent events on financial markets, UK banks and economic conditions. The Governor noted that UK banks are well capitalised, liquid and resilient to continue supporting households and businesses.
## Providing further detail about this work, Sam Woods explained that the FPC and the PRA had been closely examining developments across the financial system as a whole.
Now, we just need to build a loop to scrape the metadata for all the minutes. To avoid overloading the BoE website, we set a delay between navigating to the different URLs.
delay <- session$delay
We will also use the TryCatch() function to avoid breaking the loop in case of error (for instance when a page is not loaded correctly).
errors <- list()
metadata <- vector(mode = "list", length = nrow(minutes_urls))
for(i in minutes_urls$hyperlink){
tryCatch({
page <- read_html(i)
cat(paste("Now scraping URL: ", i, "\n"))
Sys.sleep(delay)
extracted_title <- page %>%
html_nodes("h1") %>%
html_text()
extracted_date <- page %>%
html_nodes(".published-date") %>%
html_text(trim = TRUE) %>%
str_extract("\\d+ [A-z]+ \\d+$") %>%
dmy()
abstract <- page %>%
html_nodes(".hero") %>%
html_text(trim= TRUE) %>%
list()
text <- page %>%
# We extract the titles and the text together
html_nodes('.page-section .content-block h2 , .page-section .content-block h3, .page-section .content-block .page-content p') %>%
html_text() %>%
list()
metadata[[i]] <- tibble(title = extracted_title,
url = i,
date = extracted_date,
abstract = abstract,
text = text)
}, error = function(e) {
cat(paste("Problem with scraping URL: ", i, "\n"))
errors[[i]] <- i
})
}
minutes_metadata <- bind_rows(metadata)
minutes_metadata
When all documents have their own webpage, the sitemap data becomes a powerful piece of information to facilitate your scraping. Here, it can be used to easily scrape all documents published by the Bank of England. However, the structure of the page is not exactly the same within a category (the text of the minutes is not available on the webpages before 2022 but you can scrape the URL of the PDF), and between categories (e.g., look at a speech or a working paper). Consequently, a more refined code is needed. So a more sophisticated script can be found here.
References
Harrison, John. 2022. RSelenium: R Bindings for ’Selenium WebDriver’. https://CRAN.R-project.org/package=RSelenium.
Perepolkin, Dmytro. 2023. Polite: Be Nice on the Web. https://CRAN.R-project.org/package=polite.
Wickham, Hadley. 2022. Rvest: Easily Harvest (Scrape) Web Pages. https://CRAN.R-project.org/package=rvest.
This method is inspired from a script initially written by François Claveau and Jérémie Dion for a research project about the Bank of England. ↩︎
Actually, the same method could be used for scraping the speeches of the Bank of International Settlements database. ↩︎
Aurélien Goutsmedt
Post-Doctoral Researcher
My research interests include history of economics, economic expertise and bibliometrics.